目标
给你一个整数数组 nums ,其中 nums[i] 表示第 i 个袋子里球的数目。同时给你一个整数 maxOperations 。
你可以进行如下操作至多 maxOperations 次:
- 选择任意一个袋子,并将袋子里的球分到 2 个新的袋子中,每个袋子里都有 正整数 个球。
- 比方说,一个袋子里有 5 个球,你可以把它们分到两个新袋子里,分别有 1 个和 4 个球,或者分别有 2 个和 3 个球。
你的开销是单个袋子里球数目的 最大值 ,你想要 最小化 开销。
请你返回进行上述操作后的最小开销。
示例 1:
输入:nums = [9], maxOperations = 2
输出:3
解释:
- 将装有 9 个球的袋子分成装有 6 个和 3 个球的袋子。[9] -> [6,3] 。
- 将装有 6 个球的袋子分成装有 3 个和 3 个球的袋子。[6,3] -> [3,3,3] 。
装有最多球的袋子里装有 3 个球,所以开销为 3 并返回 3 。示例 2:
输入:nums = [2,4,8,2], maxOperations = 4
输出:2
解释:
- 将装有 8 个球的袋子分成装有 4 个和 4 个球的袋子。[2,4,8,2] -> [2,4,4,4,2] 。
- 将装有 4 个球的袋子分成装有 2 个和 2 个球的袋子。[2,4,4,4,2] -> [2,2,2,4,4,2] 。
- 将装有 4 个球的袋子分成装有 2 个和 2 个球的袋子。[2,2,2,4,4,2] -> [2,2,2,2,2,4,2] 。
- 将装有 4 个球的袋子分成装有 2 个和 2 个球的袋子。[2,2,2,2,2,4,2] -> [2,2,2,2,2,2,2,2] 。
装有最多球的袋子里装有 2 个球,所以开销为 2 并返回 2 。示例 3:
输入:nums = [7,17], maxOperations = 2
输出:7说明:
1 <= nums.length <= 10^5
1 <= maxOperations, nums[i] <= 10^9
思路
有 n 个袋子,nums[i] 表示第 i + 1 个袋子中球的数目。每次操作可以任选一个袋子,将其中的球分成非空的两部分并装入两个 新 袋子。求执行 maxOperations 次操作后袋中球的数量最大值的最小值是多少。
考虑暴力解法,要最小化最大值,我们应该首先操作球最多的袋子,划分方案有 max / 2 种。这里需要枚举所有划分方案,然后重新计算球最多的袋子重复这一处理流程。最坏的情况下所有元素值都相等,时间复杂度为 O((max/2)^maxOperations)。这种解法显然行不通。
既然正向思维行不通,那就考虑逆向思维。假定一个最大值 mid,看能否在 maxOperations 次操作内将所有袋子种的球都降到 mid 以下。
将数字 num 拆分成不大于 mid 的数字最少需要操作几次?这里可以使用贪心思想,将 num 拆分为 num - mid 和 mid,然后接着拆分 num - mid 直到它小于等于 mid。
关于次数的计算,如果 num % mid == 0,我们只需划分 num / mid - 1 次,因为剩余的部分为 mid。如果余数不为 0,则需要划分 num / mid 次。以上两种情况可以统一写成 (num - 1) / mid。
代码
/**
* @date 2025-02-12 0:03
*/
public class MinimumSize1760 {
public int minimumSize(int[] nums, int maxOperations) {
int left = 1, right = 1000000000;
int mid = left + (right - left) / 2;
while (left <= right) {
if (check(nums, mid, maxOperations)) {
right = mid - 1;
} else {
left = mid + 1;
}
mid = left + (right - left) / 2;
}
return left;
}
public boolean check(int[] nums, int mid, int maxOperations) {
for (int num : nums) {
maxOperations -= (num - 1) / mid;
if (maxOperations < 0) {
return false;
}
}
return true;
}
}
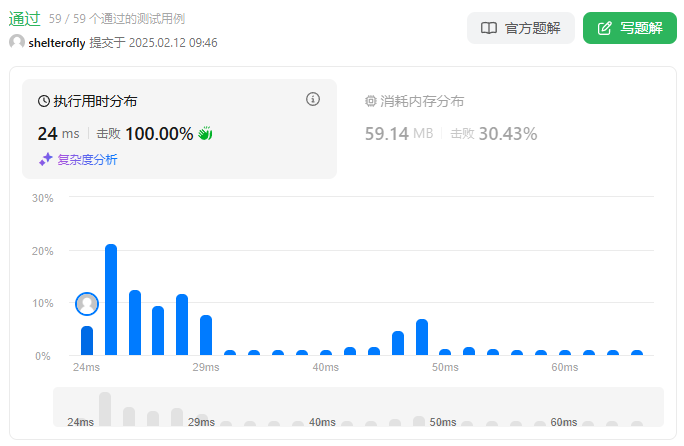
性能