目标
给你一个整数 n 。现有一个包含 n 个顶点的 无向 图,顶点按从 0 到 n - 1 编号。给你一个二维整数数组 edges 其中 edges[i] = [ai, bi] 表示顶点 ai 和 bi 之间存在一条 无向 边。
返回图中 完全连通分量 的数量。
如果在子图中任意两个顶点之间都存在路径,并且子图中没有任何一个顶点与子图外部的顶点共享边,则称其为 连通分量 。
如果连通分量中每对节点之间都存在一条边,则称其为 完全连通分量 。
示例 1:
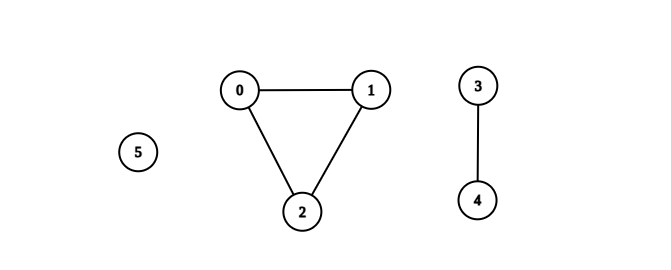
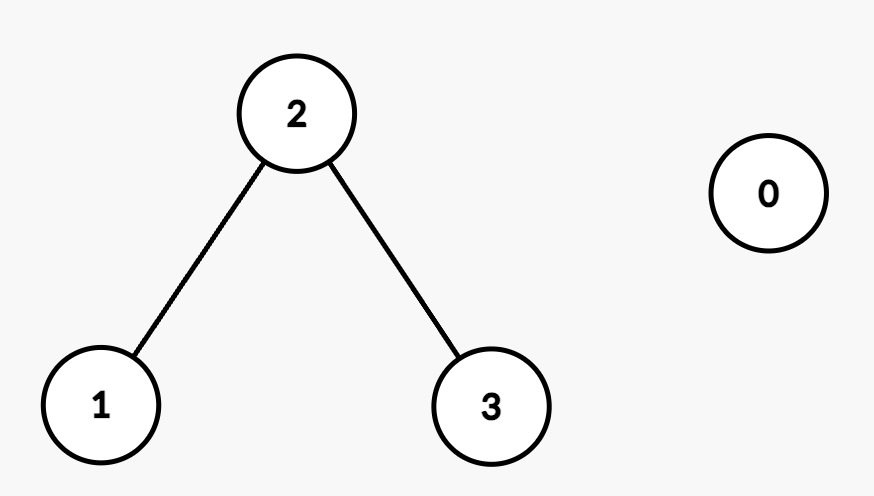
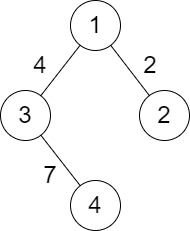
输入:n = 6, edges = [[0,1],[0,2],[1,2],[3,4]]
输出:3
解释:如上图所示,可以看到此图所有分量都是完全连通分量。示例 2:
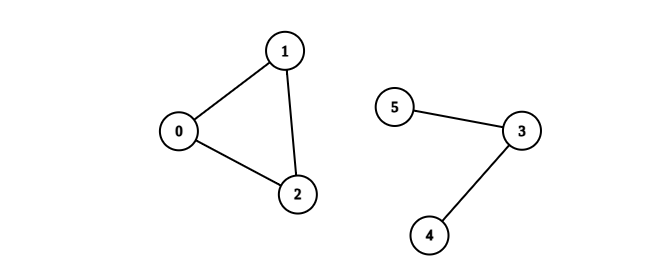
输入:n = 6, edges = [[0,1],[0,2],[1,2],[3,4],[3,5]]
输出:1
解释:包含节点 0、1 和 2 的分量是完全连通分量,因为每对节点之间都存在一条边。
包含节点 3 、4 和 5 的分量不是完全连通分量,因为节点 4 和 5 之间不存在边。
因此,在图中完全连接分量的数量是 1 。说明:
- 1 <= n <= 50
- 0 <= edges.length <= n * (n - 1) / 2
- edges[i].length == 2
- 0 <= ai, bi <= n - 1
- ai != bi
- 不存在重复的边
思路
求无向图中完全连通分量的个数。完全连通分量指连通分量中任意两个节点之间都有一条边。
暴力解法是使用并查集维护连通分量,找出同一连通分量内的节点,判断两两之间是否有边。
优化点:可以利用节点与边的关系来判断是否是完全连通分量,节点 v 与 边 e 的关系为:e = C(v, 2) = v * (v - 1) / 2。
代码
/**
* @date 2026-07-14 11:27
*/
public class CountCompleteComponents2685 {
private class UnionFind {
private final int[] fa;
public UnionFind(int n) {
fa = new int[n];
Arrays.setAll(fa, i -> i);
}
public int find(int e) {
if (e != fa[e]) {
fa[e] = find(fa[e]);
}
return fa[e];
}
public void union(int a, int b) {
int x = find(a);
int y = find(b);
if (x > y) {
fa[x] = y;
} else {
fa[y] = x;
}
}
public int getCompleteComponents(Set<Integer>[] g) {
int n = fa.length;
int res = 0;
Set<Integer> visited = new HashSet<>();
for (int i = 0; i < n; i++) {
if (visited.contains(i)) {
continue;
}
visited.add(i);
List<Integer> list = new ArrayList<>();
for (int j = 0; j < n; j++) {
if (find(j) == find(i)) {
visited.add(j);
list.add(j);
}
}
int size = list.size();
boolean flag = true;
here:
for (int p = 0; p < size; p++) {
for (int q = p + 1; q < size; q++) {
if (!g[list.get(p)].contains(list.get(q))) {
flag = false;
break here;
}
}
}
if (flag) {
res++;
}
}
return res;
}
}
public int countCompleteComponents(int n, int[][] edges) {
UnionFind uf = new UnionFind(n);
Set<Integer>[] g = new HashSet[n];
Arrays.setAll(g, x -> new HashSet<>());
for (int[] edge : edges) {
int a = edge[0];
int b = edge[1];
uf.union(a, b);
g[a].add(b);
g[b].add(a);
}
return uf.getCompleteComponents(g);
}
}
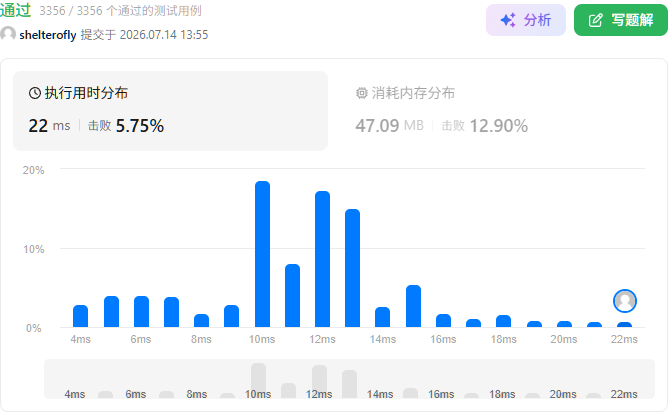
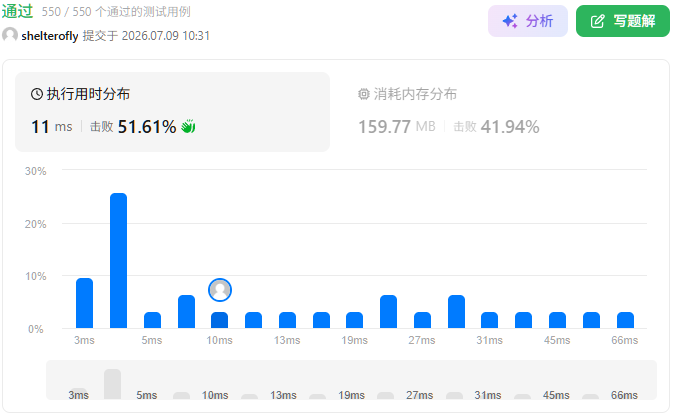
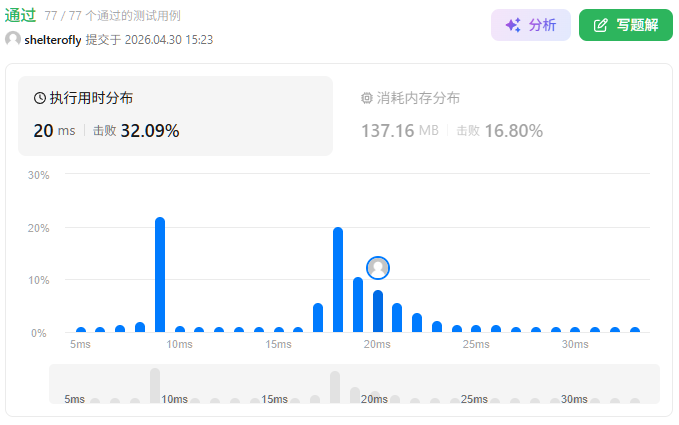
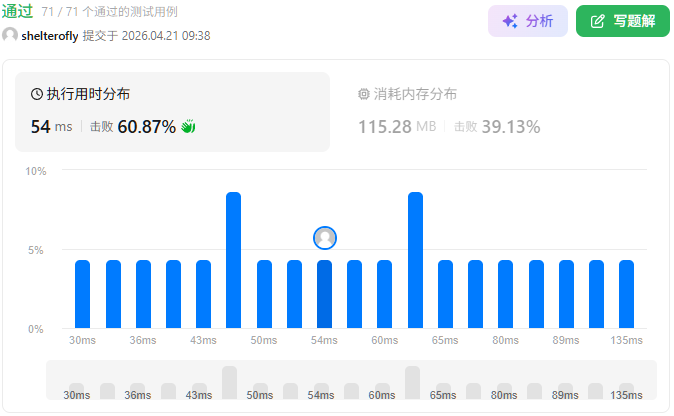
性能