目标
给你一个整数数组 nums 。
XOR 三元组 定义为三个元素的异或值 nums[i] XOR nums[j] XOR nums[k],其中 i <= j <= k。
返回所有可能三元组 (i, j, k) 中 不同 的 XOR 值的数量。
示例 1:
输入: nums = [1,3]
输出: 2
解释:
所有可能的 XOR 三元组值为:
(0, 0, 0) → 1 XOR 1 XOR 1 = 1
(0, 0, 1) → 1 XOR 1 XOR 3 = 3
(0, 1, 1) → 1 XOR 3 XOR 3 = 1
(1, 1, 1) → 3 XOR 3 XOR 3 = 3
不同的 XOR 值为 {1, 3} 。因此输出为 2 。示例 2:
输入: nums = [6,7,8,9]
输出: 4
解释:
不同的 XOR 值为 {6, 7, 8, 9} 。因此输出为 4 。说明:
1 <= nums.length <= 1500
1 <= nums[i] <= 1500
思路
有一个正整数数组 nums,从中取三个数(可重复)的异或值 XOR,求不同的 XOR 值有多少个。
暴力枚举。
代码
/**
* @date 2026-07-24 9:12
*/
public class UniqueXorTriplets3514 {
public int uniqueXorTriplets(int[] nums) {
int n = nums.length;
int max = 0;
for (int num : nums) {
max = Math.max(max, num);
}
int upper = 1 << (32 - Integer.numberOfLeadingZeros(max));
boolean[] tmp = new boolean[upper];
boolean[] arr = new boolean[upper];
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
tmp[nums[i] ^ nums[j]] = true;
}
}
for (int i = 0; i < upper; i++) {
if (tmp[i]) {
for (int num : nums) {
arr[num ^ i] = true;
}
}
}
int res = 0;
for (boolean b : arr) {
if (b) {
res++;
}
}
return res;
}
}
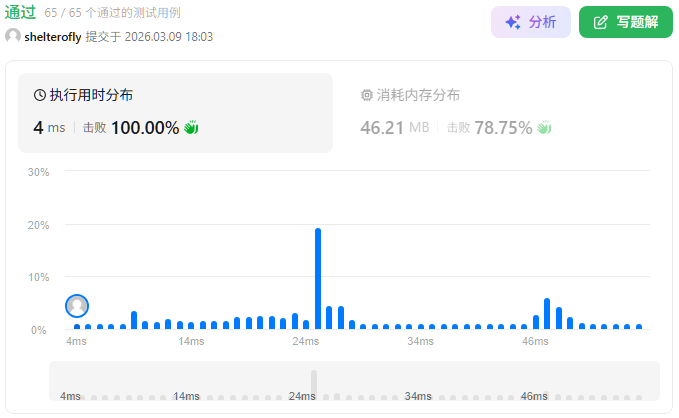
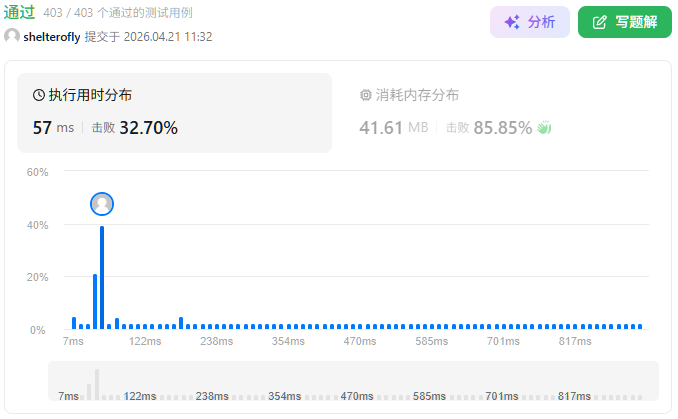
性能