目标
一个数组的 分数 定义为数组之和 乘以 数组的长度。
- 比方说,[1, 2, 3, 4, 5] 的分数为 (1 + 2 + 3 + 4 + 5) * 5 = 75 。
给你一个正整数数组 nums 和一个整数 k ,请你返回 nums 中分数 严格小于 k 的 非空整数子数组数目。
子数组 是数组中的一个连续元素序列。
示例 1:
输入:nums = [2,1,4,3,5], k = 10
输出:6
解释:
有 6 个子数组的分数小于 10 :
- [2] 分数为 2 * 1 = 2 。
- [1] 分数为 1 * 1 = 1 。
- [4] 分数为 4 * 1 = 4 。
- [3] 分数为 3 * 1 = 3 。
- [5] 分数为 5 * 1 = 5 。
- [2,1] 分数为 (2 + 1) * 2 = 6 。
注意,子数组 [1,4] 和 [4,3,5] 不符合要求,因为它们的分数分别为 10 和 36,但我们要求子数组的分数严格小于 10 。示例 2:
输入:nums = [1,1,1], k = 5
输出:5
解释:
除了 [1,1,1] 以外每个子数组分数都小于 5 。
[1,1,1] 分数为 (1 + 1 + 1) * 3 = 9 ,大于 5 。
所以总共有 5 个子数组得分小于 5 。说明:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^5
- 1 <= k <= 10^15
思路
统计 正整数 数组中 子数组元素和 * 子数组长度 < k 的子数组个数。
统计满足条件的子数组个数,首先考虑滑动窗口。枚举右端点 right,只要 [left, right] 的分数小于 k,那么任意以 i ∈ [left, right] 为左端点的子数组的分数都小于 k,共有 right - left + 1 个。如果窗口内的分数大于等于 k,需要移出左端点,直到窗口内的分数小于 k。
代码
/**
* @date 2025-04-28 8:41
*/
public class CountSubarrays2302 {
public long countSubarrays(int[] nums, long k) {
long res = 0L;
int n = nums.length;
int left = 0;
long sum = 0L;
int len = 0;
for (int right = 0; right < n; right++) {
sum += nums[right];
len++;
while (left < n && sum * len >= k) {
sum -= nums[left++];
len--;
}
res += right - left + 1;
}
return res;
}
}
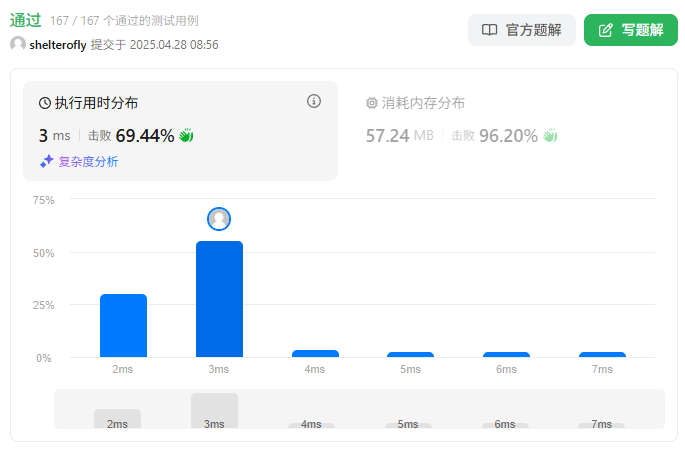
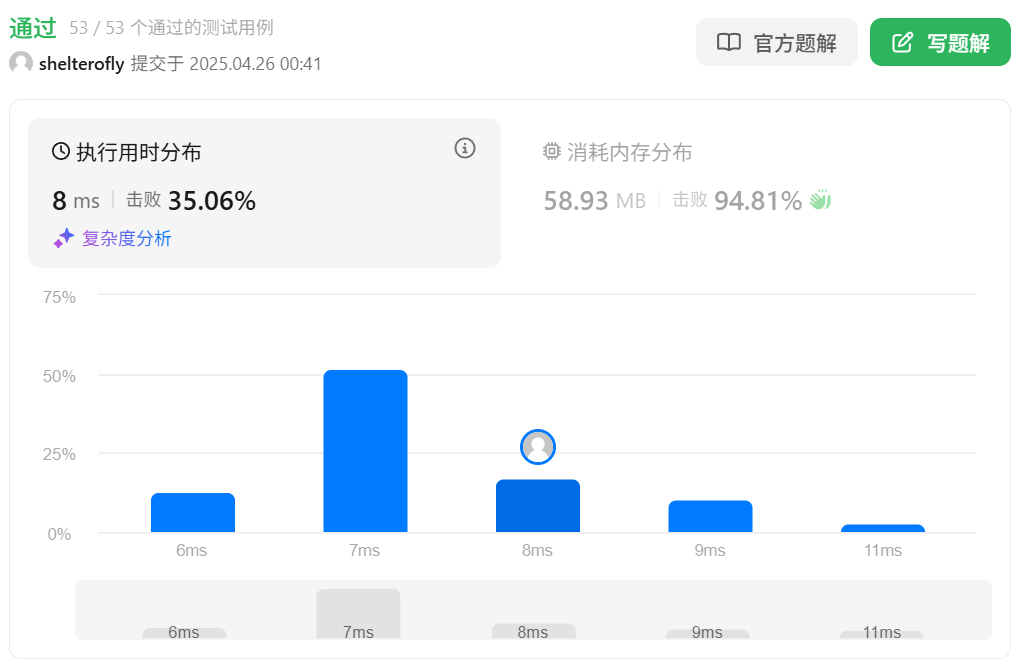
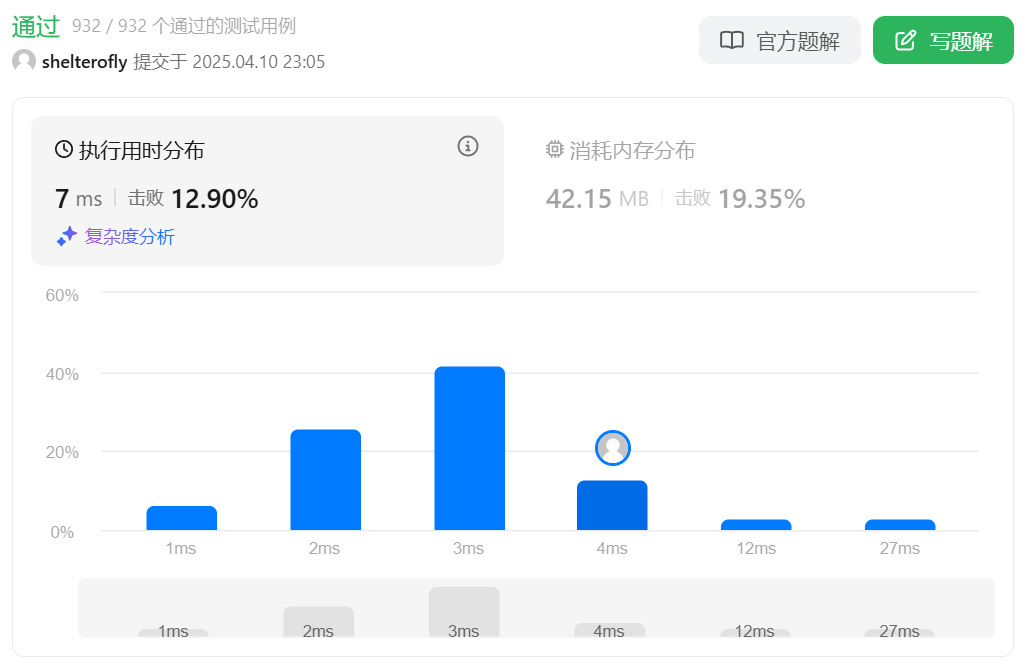
性能