目标
给你一个 回文 字符串 s。
返回 s 的按字典序排列的 最小 回文排列。
如果一个字符串从前往后和从后往前读都相同,那么这个字符串是一个 回文 字符串。
排列 是字符串中所有字符的重排。
如果字符串 a 按字典序小于字符串 b,则表示在第一个不同的位置,a 中的字符比 b 中的对应字符在字母表中更靠前。
如果在前 min(a.length, b.length) 个字符中没有区别,则较短的字符串按字典序更小。
示例 1:
输入: s = "z"
输出: "z"
解释:
仅由一个字符组成的字符串已经是按字典序最小的回文。示例 2:
输入: s = "babab"
输出: "abbba"
解释:
通过重排 "babab" → "abbba",可以得到按字典序最小的回文。示例 3:
输入: s = "daccad"
输出: "acddca"
解释:
通过重排 "daccad" → "acddca",可以得到按字典序最小的回文。说明:
- 1 <= s.length <= 10^5
- s 由小写英文字母组成。
- 保证 s 是回文字符串。
思路
有一个回文字符串 s,将其重新排列成回文字符串,使得字典序最小。
记录字符串中字符的出现次数,然后按字典序从两边向中间填充,如果出现次数为奇数,那么该字符为中间元素。
代码
/**
* @date 2026-07-28 9:03
*/
public class SmallestPalindrome3517 {
public String smallestPalindrome(String s) {
int[] cnt = new int[26];
int n = s.length();
char[] res = new char[n];
for (char c : s.toCharArray()) {
cnt[c - 'a']++;
}
char mid = 0;
int cur = 0;
for (int i = 0; i < 26; i++) {
if (cnt[i] % 2 == 1) {
mid = (char) ('a' + i);
}
int k = cnt[i] / 2;
char c = (char) ('a' + i);
for (int j = 0; j < k; j++) {
res[cur + j] = c;
res[n - cur - j - 1] = c;
}
cur += k;
}
if (n % 2 == 1) {
res[n / 2] = mid;
}
return new String(res);
}
}
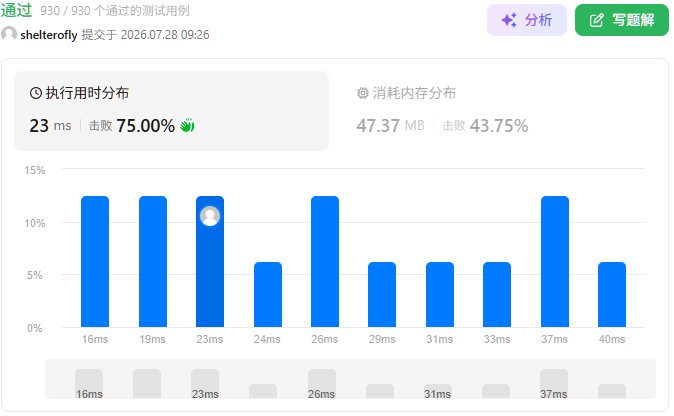
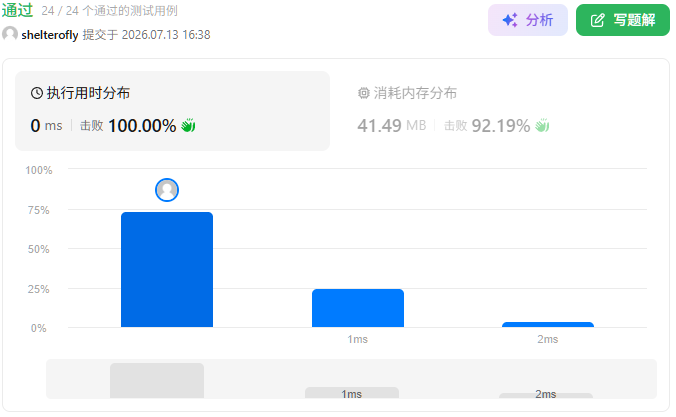
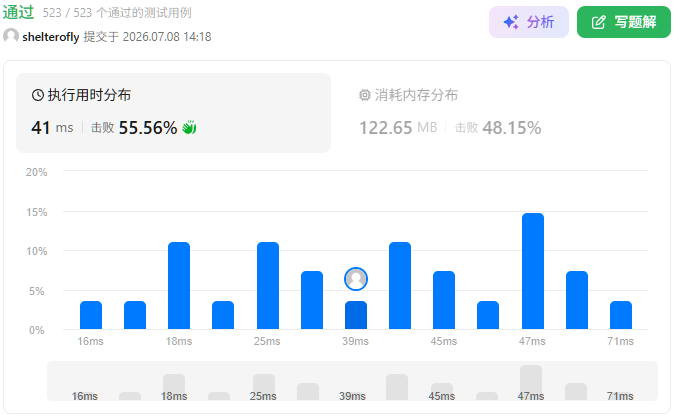
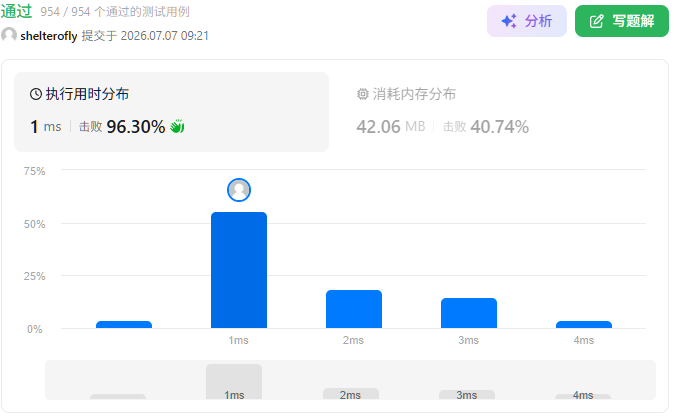
性能