目标
给定 m 个数组,每个数组都已经按照升序排好序了。
现在你需要从两个不同的数组中选择两个整数(每个数组选一个)并且计算它们的距离。两个整数 a 和 b 之间的距离定义为它们差的绝对值 |a-b| 。
返回最大距离。
示例 1:
输入:[[1,2,3],[4,5],[1,2,3]]
输出:4
解释:
一种得到答案 4 的方法是从第一个数组或者第三个数组中选择 1,同时从第二个数组中选择 5 。示例 2:
输入:arrays = [[1],[1]]
输出:0说明:
- m == arrays.length
- 2 <= m <= 10^5
- 1 <= arrays[i].length <= 500
- -10^4 <=
arrays[i][j]<= 10^4 - arrays[i] 以 升序 排序。
- 所有数组中最多有 10^5 个整数。
思路
有一个二维数组,其中的每个数组都按升序排列。任选其中两个数组,从每个数组中选两个元素,求这两个元素距离的最大值,距离指差的绝对值。
显然应该选取最大值与最小值的差,但题目限制是从两个数组中取。我们可以求得最大与次最大、最小与次最小,同时记录所属数组。
如果有多个最值相同,从哪个数组中取有影响吗?由于我们从每个组只取首尾两个元素,最值与次最值一定来自不同的组,所以最值的比较可以使用 >= 和 <=。如果最值来自相同的组,那么只需比较最大值与次最小值,次最大值与最小值。
网友题解使用变量记录前面的最大与最小值,那么最大距离为 Math.max(res, Math.max(curMax - preMin, preMax - curMin))。
代码
/**
* @date 2025-02-19 8:57
*/
public class MaxDistance624 {
public int maxDistance_v1(List<List<Integer>> arrays) {
int res = 0;
int preMax = Integer.MIN_VALUE / 2;
int preMin = Integer.MAX_VALUE / 2;
for (List<Integer> array : arrays) {
int n = array.size();
Integer curMax = array.get(n - 1);
Integer curMin = array.get(0);
res = Math.max(res, Math.max(curMax - preMin, preMax - curMin));
preMax = Math.max(preMax, curMax);
preMin = Math.min(preMin, curMin);
}
return res;
}
public int maxDistance(List<List<Integer>> arrays) {
int[] max = new int[]{Integer.MIN_VALUE, -1};
int secondMax = Integer.MIN_VALUE;
int[] min = new int[]{Integer.MAX_VALUE, -1};
int secondMin = Integer.MAX_VALUE;
for (int i = 0; i < arrays.size(); i++) {
List<Integer> array = arrays.get(i);
int n = array.size();
if (min[0] >= array.get(0)) {
secondMin = min[0];
min[0] = array.get(0);
min[1] = i;
} else if (secondMin > array.get(0)) {
secondMin = array.get(0);
}
if (max[0] <= array.get(n - 1)) {
secondMax = max[0];
max[0] = array.get(n - 1);
max[1] = i;
} else if (secondMax < array.get(n - 1)) {
secondMax = array.get(n - 1);
}
}
if (max[1] != min[1]) {
return max[0] - min[0];
} else {
return Math.max(max[0] - secondMin, secondMax - min[0]);
}
}
}
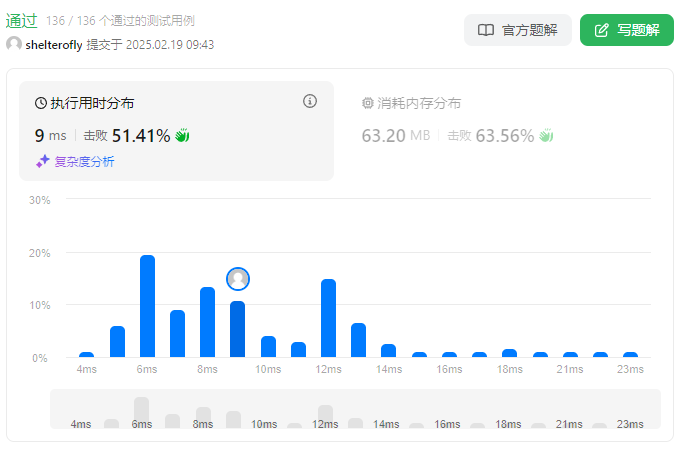
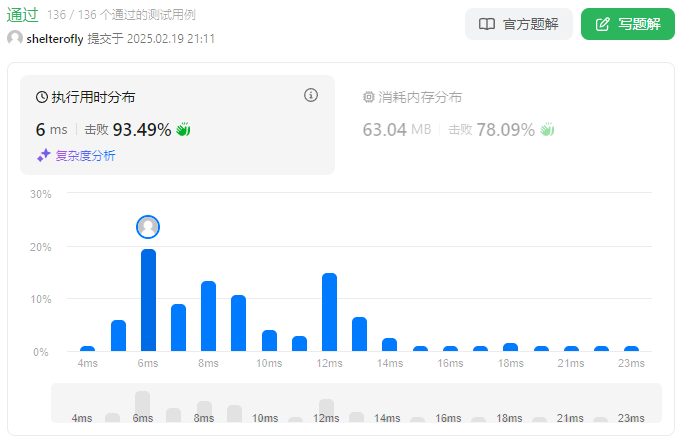
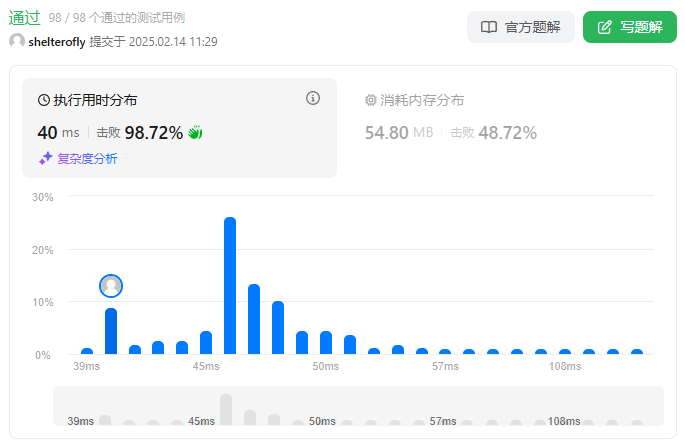
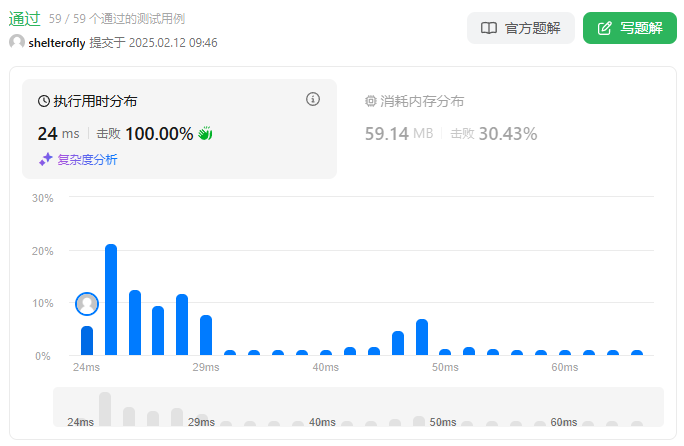
性能