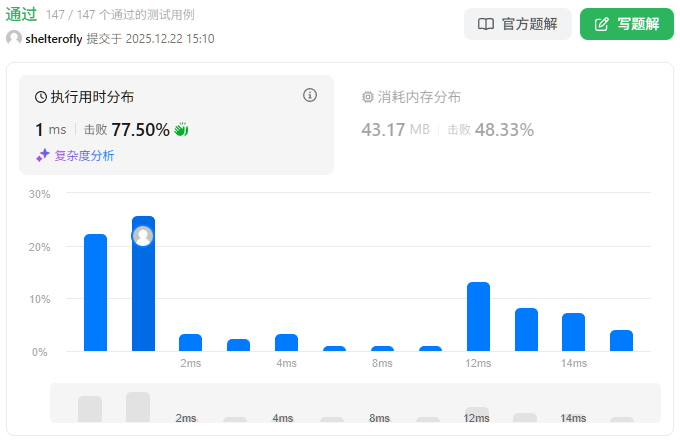
目标
有一个大型的 (m - 1) x (n - 1) 矩形田地,其两个对角分别是 (1, 1) 和 (m, n) ,田地内部有一些水平栅栏和垂直栅栏,分别由数组 hFences 和 vFences 给出。
水平栅栏为坐标 (hFences[i], 1) 到 (hFences[i], n),垂直栅栏为坐标 (1, vFences[i]) 到 (m, vFences[i]) 。
返回通过 移除 一些栅栏(可能不移除)所能形成的最大面积的 正方形 田地的面积,或者如果无法形成正方形田地则返回 -1。
由于答案可能很大,所以请返回结果对 10^9 + 7 取余 后的值。
注意:田地外围两个水平栅栏(坐标 (1, 1) 到 (1, n) 和坐标 (m, 1) 到 (m, n) )以及两个垂直栅栏(坐标 (1, 1) 到 (m, 1) 和坐标 (1, n) 到 (m, n) )所包围。这些栅栏 不能 被移除。
示例 1:
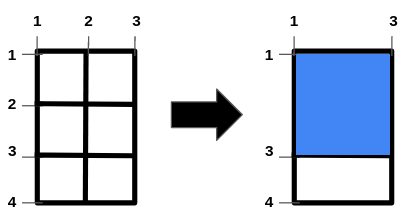
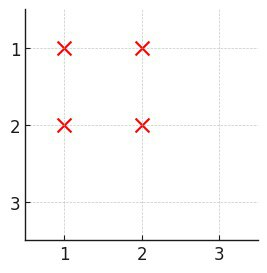
输入:m = 4, n = 3, hFences = [2,3], vFences = [2]
输出:4
解释:移除位于 2 的水平栅栏和位于 2 的垂直栅栏将得到一个面积为 4 的正方形田地。示例 2:

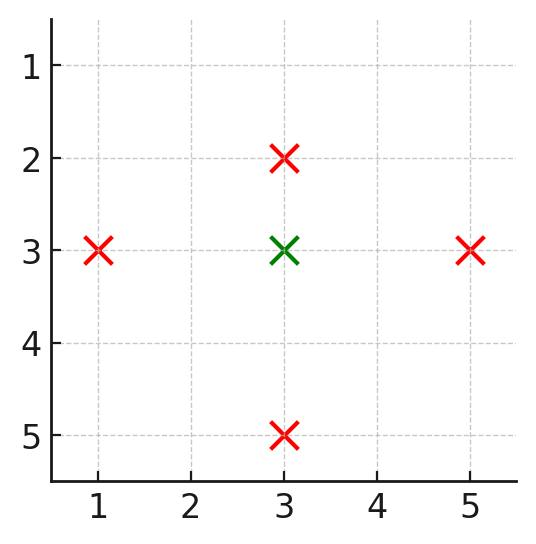
输入:m = 6, n = 7, hFences = [2], vFences = [4]
输出:-1
解释:可以证明无法通过移除栅栏形成正方形田地。说明:
- 3 <= m, n <= 10^9
- 1 <= hFences.length, vFences.length <= 600
- 1 < hFences[i] < m
- 1 < vFences[i] < n
- hFences 和 vFences 中的元素是唯一的。
思路
有一个 (m - 1) x (n - 1) 矩形田地,左上角坐标为 (1, 1),右下角坐标为 (m, n),田地内部有一些栅栏,水平栅栏 i 的纵坐标为 hFences[i],垂直栅栏 j 的横坐标为 vFences[j]。可以移除一些栅栏,求能够形成的最大正方形的面积。
使用哈希表分别记录水平与垂直方向可能的间隔,找到最大相等间隔,相乘即可。
代码
/**
* @date 2026-01-16 8:49
*/
public class MaximizeSquareArea2975 {
public int maximizeSquareArea(int m, int n, int[] hFences, int[] vFences) {
Set<Integer> hq = getInterval(m, hFences);
Set<Integer> vq = getInterval(n, vFences);
hq.retainAll(vq);
if (hq.size() == 0) {
return -1;
}
long res = 0;
int mod = 1000000007;
for (Integer num : hq) {
res = Math.max(res, num);
}
return (int) (res * res % mod);
}
private Set<Integer> getInterval(int edge, int[] fences) {
Arrays.sort(fences);
Set<Integer> set = new HashSet<>();
int n = fences.length;
for (int i = 0; i < n; i++) {
set.add(fences[i] - 1);
set.add(edge - fences[i]);
for (int j = i + 1; j < n; j++) {
set.add(fences[j] - fences[i]);
}
}
set.add(edge - 1);
return set;
}
}
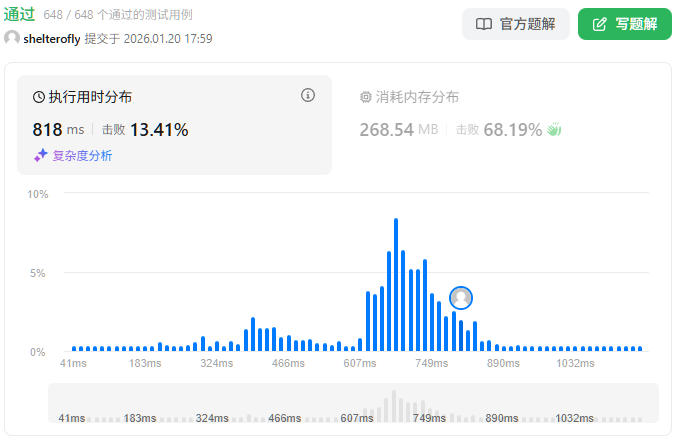
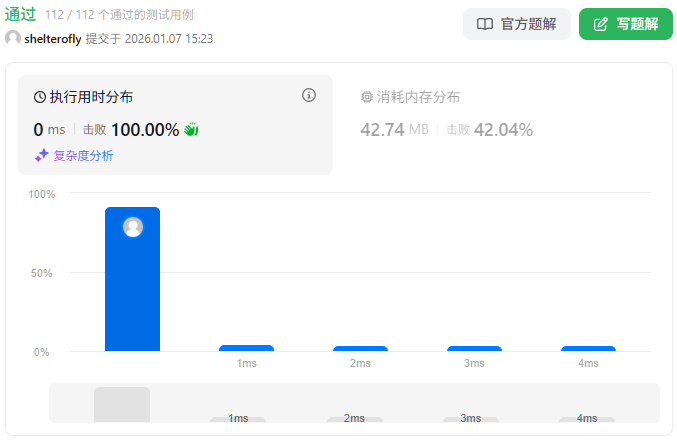
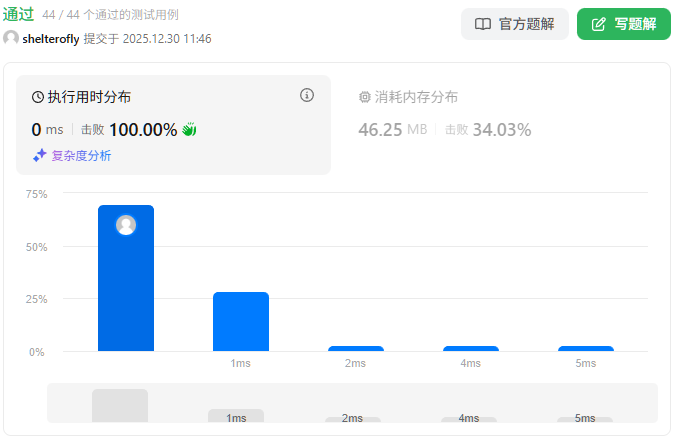
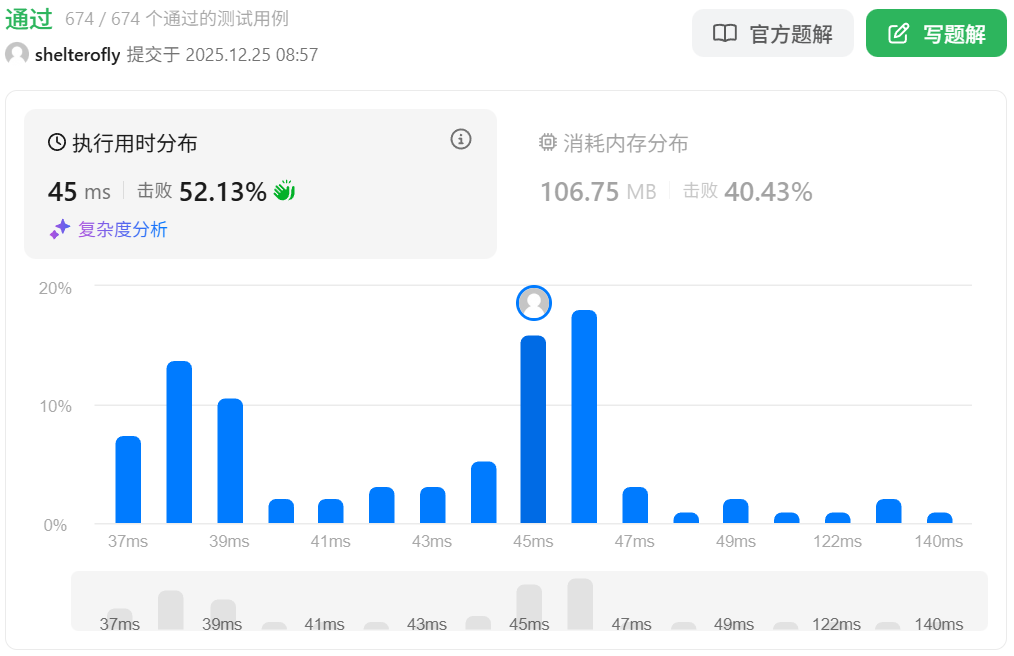
性能