排序后去掉工资最高与最低的求平均值。
其实不需要排序,只需找到最大与最小值,然后从总和里减去即可。
排序后去掉工资最高与最低的求平均值。
其实不需要排序,只需找到最大与最小值,然后从总和里减去即可。
有 n 名工人。 给定两个数组 quality 和 wage ,其中,quality[i] 表示第 i 名工人的工作质量,其最低期望工资为 wage[i] 。
现在我们想雇佣 k 名工人组成一个工资组。在雇佣 一组 k 名工人时,我们必须按照下述规则向他们支付工资:
给定整数 k ,返回 组成满足上述条件的付费群体所需的最小金额 。在实际答案的 10^-5 以内的答案将被接受。
示例 1:
输入: quality = [10,20,5], wage = [70,50,30], k = 2
输出: 105.00000
解释: 我们向 0 号工人支付 70,向 2 号工人支付 35。示例 2:
输入: quality = [3,1,10,10,1], wage = [4,8,2,2,7], k = 3
输出: 30.66667
解释: 我们向 0 号工人支付 4,向 2 号和 3 号分别支付 13.33333。说明:
从quality中选k个,按照工作质量比例支付工资,并且每人的工资不能低于wage中的最低期望工资,问雇佣这k个人的最低成本是多少。
// todo
/**
* @date 2024-05-02 20:44
*/
public class MincostToHireWorkers857 {
public double mincostToHireWorkers(int[] quality, int[] wage, int k) {
int n = wage.length;
PriorityQueue<double[]> wqq = new PriorityQueue<>(Comparator.comparingDouble(x -> x[0]));
double[][] wq = new double[n][2];
for (int i = 0; i < wage.length; i++) {
wq[i][0] = (double) wage[i] / quality[i];
wq[i][1] = i;
wqq.offer(wq[i]);
}
PriorityQueue<Integer> q = new PriorityQueue<>((x, y) -> y - x);
int sum = 0;
int ri = 0;
for (int i = 0; i < k; i++) {
double[] choose = wqq.poll();
int index = (int) choose[1];
sum += quality[index];
q.offer(quality[index]);
ri = (int) choose[1];
}
double res = (double) sum * wage[ri] / quality[ri];
while (!wqq.isEmpty()) {
double[] choose = wqq.poll();
int index = (int) choose[1];
if (q.peek() > quality[index]) {
sum = sum - q.peek() + quality[index];
double resTmp = (double)sum * wage[index] / quality[index];
q.poll();
q.offer(quality[index]);
if (res > resTmp) {
res = resTmp;
}
}
}
return res;
}
}
给你一个下标从 0 开始的整数数组 costs ,其中 costs[i] 是雇佣第 i 位工人的代价。
同时给你两个整数 k 和 candidates 。我们想根据以下规则恰好雇佣 k 位工人:
返回雇佣恰好 k 位工人的总代价。
示例 1:
输入:costs = [17,12,10,2,7,2,11,20,8], k = 3, candidates = 4
输出:11
解释:我们总共雇佣 3 位工人。总代价一开始为 0 。
- 第一轮雇佣,我们从 [17,12,10,2,7,2,11,20,8] 中选择。最小代价是 2 ,有两位工人,我们选择下标更小的一位工人,即第 3 位工人。总代价是 0 + 2 = 2 。
- 第二轮雇佣,我们从 [17,12,10,7,2,11,20,8] 中选择。最小代价是 2 ,下标为 4 ,总代价是 2 + 2 = 4 。
- 第三轮雇佣,我们从 [17,12,10,7,11,20,8] 中选择,最小代价是 7 ,下标为 3 ,总代价是 4 + 7 = 11 。注意下标为 3 的工人同时在最前面和最后面 4 位工人中。
总雇佣代价是 11 。示例 2:
输入:costs = [1,2,4,1], k = 3, candidates = 3
输出:4
解释:我们总共雇佣 3 位工人。总代价一开始为 0 。
- 第一轮雇佣,我们从 [1,2,4,1] 中选择。最小代价为 1 ,有两位工人,我们选择下标更小的一位工人,即第 0 位工人,总代价是 0 + 1 = 1 。注意,下标为 1 和 2 的工人同时在最前面和最后面 3 位工人中。
- 第二轮雇佣,我们从 [2,4,1] 中选择。最小代价为 1 ,下标为 2 ,总代价是 1 + 1 = 2 。
- 第三轮雇佣,少于 3 位工人,我们从剩余工人 [2,4] 中选择。最小代价是 2 ,下标为 0 。总代价为 2 + 2 = 4 。
总雇佣代价是 4 。说明:
给我们一个数组 costs 和一个整数 candidates,每次从数组的前candidates与后candidates中选取值最小的元素,如果最小值相等则取下标最小的,costs中的每个值只能被选一次,求选出的k个元素和。
很直接的想法是使用优先队列保存这些元素,考虑到相同值需要取下标最小的,于是还要保存下标信息。循环从队列取出头元素累加到res,每取出一个元素需要从前/后补一个元素到队列中。
注意题目的数据范围,需要返回long类型。还有就是放队列以及补元素的停止条件以免重复。
/**
* @date 2024-05-01 17:03
*/
public class TotalCost2462 {
public long totalCost(int[] costs, int k, int candidates) {
PriorityQueue<Integer[]> q = new PriorityQueue<>((x, y) -> {
int compare = x[0] - y[0];
return compare == 0 ? x[1] - y[1] : compare;
});
int n = costs.length;
int leftPos;
int rightPos = n - 1;
for (leftPos = 0; leftPos < candidates; leftPos++) {
if (leftPos < rightPos) {
// rightPos 与 leftPos指向的都是需要添加的下一个位置,
q.offer(new Integer[]{costs[leftPos], leftPos});
q.offer(new Integer[]{costs[rightPos], rightPos});
rightPos--;
}
else if (leftPos == rightPos) {
// 这里已经覆盖了数组的所有元素,循环结束后leftPos > rightPos
q.offer(new Integer[]{costs[leftPos], leftPos});
}
else {
break;
}
}
// 不使用long会溢出
long res = 0;
// 选到最小之后,补够candidates
for (int i = 0; i < k && !q.isEmpty(); i++) {
Integer[] c = q.poll();
res += c[0];
// 如果已经覆盖了所有元素就无需再添加了
if (leftPos > rightPos) {
continue;
}
if (c[1] < leftPos) {
q.offer(new Integer[]{costs[leftPos], leftPos});
leftPos++;
} else if (c[1] > rightPos) {
q.offer(new Integer[]{costs[rightPos], rightPos});
rightPos--;
}
}
return res;
}
}勉强通过,官网也是这个思路,耗时82ms。有网友的解法是分别使用了两个优先队列,只需要22ms。

明天五一假期。今天的题太友好了,循环里面判断就行了。
矩阵对角线 是一条从矩阵最上面行或者最左侧列中的某个元素开始的对角线,沿右下方向一直到矩阵末尾的元素。例如,矩阵 mat 有 6 行 3 列,从 mat[2][0] 开始的 矩阵对角线 将会经过 mat[2][0]、mat[3][1] 和 mat[4][2] 。
给你一个 m * n 的整数矩阵 mat ,请你将同一条 矩阵对角线 上的元素按升序排序后,返回排好序的矩阵。
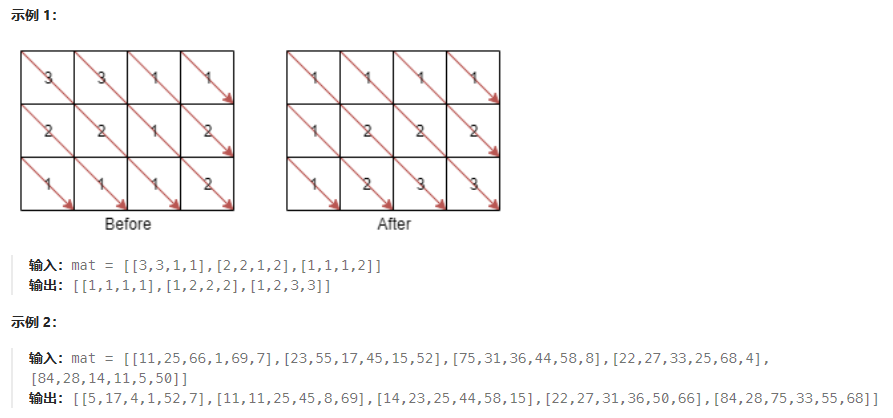
说明:
1 <= mat[i][j] <= 100排序是一大块内容,有机会统一总结一下。// todo
这里偷懒使用了优先队列,先放到队列里面排序,然后再写回去。
/**
* @date 2024-04-29 0:26
*/
public class DiagonalSort1329 {
public int[][] diagonalSort(int[][] mat) {
int m = mat.length;
int n = mat[0].length;
int i;
int j;
PriorityQueue<Integer> q = new PriorityQueue();
for (int col = 0; col < n; col++) {
j = col;
i = 0;
while (i < m && j < n) {
q.offer(mat[i++][j++]);
}
j = col;
i = 0;
while (i < m && j < n) {
mat[i++][j++] = q.poll();
}
}
for (int row = 1; row < m; row++) {
j = 0;
i = row;
while (i < m && j < n) {
q.offer(mat[i++][j++]);
}
j = 0;
i = row;
while (i < m && j < n) {
mat[i++][j++] = q.poll();
}
}
return mat;
}
}
// todo
给你一个下标从 0 开始的 m * n 整数矩阵 grid 。矩阵中某一列的宽度是这一列数字的最大 字符串长度 。
请你返回一个大小为 n 的整数数组 ans ,其中 ans[i] 是第 i 列的宽度。
一个有 len 个数位的整数 x ,如果是非负数,那么 字符串长度 为 len ,否则为 len + 1 。
示例 1:
输入:grid = [[1],[22],[333]]
输出:[3]
解释:第 0 列中,333 字符串长度为 3 。示例 2:
输入:grid = [[-15,1,3],[15,7,12],[5,6,-2]]
输出:[3,1,2]
解释:
第 0 列中,只有 -15 字符串长度为 3 。
第 1 列中,所有整数的字符串长度都是 1 。
第 2 列中,12 和 -2 的字符串长度都为 2 。
说明:
-10^9 <= grid[r][c] <= 10^9这个题核心就是如何计算数字的长度。我们可以枚举 9, 99, 999, 9999, 99999, 999999, 9999999, 99999999, 999999999, Integer.MAX_VALUE,分别与这些值比较,Integer.stringSize就是如此实现的。对于负数需要将长度加1 int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);。
也可以循环除以10直到0来计算长度。一个优化的点是不必求每一个数的长度,只需要求出最大值 max 与 最小值 min的长度即可。网友还提供了一个小技巧可以减少对较小值的长度计算。选取 max/10 和 -min 中的较大值来计算长度 l,取 l+1。解释如下:如果 min > 0 那么 -min < 0,我们取到 max/10 的长度,所以长度为 l+1。如果 min < 0,并且 -min > max/10,我们取到 -min,长度需要加上负号,即 l+1。这里需要解释一下 -min < max && -min > max/10 的情况,这时 max 的长度与 -min 的长度加1 是相同的。而如果 min < 0,且 -min < max/10,取 max/10 长度减小了1,所以取 l+1。
/**
* @date 2024-04-27 18:39
*/
public class FindColumnWidth2639 {
int[] sizeTable = {9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, Integer.MAX_VALUE};
int stringSize(int x) {
int j;
if (x < 0) {
x = -x;
j = 2;
} else {
j = 1;
}
for (int i = 0; ; i++) {
if (x <= sizeTable[i]) {
return i + j;
}
}
}
public int[] findColumnWidth(int[][] grid) {
int n = grid[0].length;
int[] res = new int[n];
int[] negative = new int[n];
for (int[] ints : grid) {
for (int i = 0; i < n; i++) {
if (ints[i] < negative[i]) {
negative[i] = ints[i];
} else if (ints[i] > res[i]) {
res[i] = ints[i];
}
}
}
for (int i = 0; i < n; i++) {
res[i] = Math.max(stringSize(res[i]), stringSize(negative[i]));
}
return res;
}
}
这个题涉及到hash表与二分查找,发现之前2529.正整数和负整数的最大计数里面寻找上界写错了。
有时间了再整理一下吧。
卡车有两个油箱。给你两个整数,mainTank 表示主油箱中的燃料(以升为单位),additionalTank 表示副油箱中的燃料(以升为单位)。
该卡车每耗费 1 升燃料都可以行驶 10 km。每当主油箱使用了 5 升燃料时,如果副油箱至少有 1 升燃料,则会将 1 升燃料从副油箱转移到主油箱。
返回卡车可以行驶的最大距离。
注意:从副油箱向主油箱注入燃料不是连续行为。这一事件会在每消耗 5 升燃料时突然且立即发生。
示例 1:
输入:mainTank = 5, additionalTank = 10
输出:60
解释:
在用掉 5 升燃料后,主油箱中燃料还剩下 (5 - 5 + 1) = 1 升,行驶距离为 50km 。
在用掉剩下的 1 升燃料后,没有新的燃料注入到主油箱中,主油箱变为空。
总行驶距离为 60km 。示例 2:
输入:mainTank = 1, additionalTank = 2
输出:10
解释:
在用掉 1 升燃料后,主油箱变为空。
总行驶距离为 10km 。说明:
这里面的关键点在于第一次消耗完5升燃料之后会触发副油箱注入,后面消耗的5升燃料中包含有副油箱注入的1升。即第一次消耗完成后主油箱每消耗4升就会触发燃料注入。
例如主油箱有9L,副油箱有1L,那么总共可以消耗10L燃料。
注入燃料的总次数等于 1 + (mainTank -5)/4 = (mainTank - 1)/4。
/**
* @date 2024-04-25 0:11
*/
public class DistanceTraveled2739 {
public int distanceTraveled_v1(int mainTank, int additionalTank) {
return 10 * (mainTank + Math.min((mainTank - 1) / 4, additionalTank));
}
public int distanceTraveled(int mainTank, int additionalTank) {
int res = 0;
while (mainTank >= 5) {
res += 5;
mainTank -= 5;
if (additionalTank > 0) {
additionalTank--;
mainTank++;
}
}
res += mainTank;
return res * 10;
}
}
给你一棵二叉树的根节点 root ,二叉树中节点的值 互不相同 。另给你一个整数 start 。在第 0 分钟,感染 将会从值为 start 的节点开始爆发。
每分钟,如果节点满足以下全部条件,就会被感染:
返回感染整棵树需要的分钟数。
示例 1:
输入:root = [1,5,3,null,4,10,6,9,2], start = 3
输出:4
解释:节点按以下过程被感染:
- 第 0 分钟:节点 3
- 第 1 分钟:节点 1、10、6
- 第 2 分钟:节点5
- 第 3 分钟:节点 4
- 第 4 分钟:节点 9 和 2
感染整棵树需要 4 分钟,所以返回 4 。示例 2:
输入:root = [1], start = 1
输出:0
解释:第 0 分钟,树中唯一一个节点处于感染状态,返回 0 。说明:
从树中任意节点开始,每过一分钟感染会向周围扩散,问感染整棵树需要多久。
首先我们要找到感染开始的节点。从这个节点出发,向左右子树点以及父节点扩散。可以将树转换为以感染节点为起点的有向无环连通图,这样问题被转换为求起点到图中任意节点的最长路径。
如果不想建图可以考虑扩散的具体路径,刚开始很难把各种情况都考虑到。我们需要计算以开始节点为根的子树高度 h(start),并依次比较开始节点到祖先节点路径长度加上祖先另一子树高度的最大值,即max(d(start) - d(ancestor) + h(anotherAncestorSubtree)),再取二者的最大值即可。特别需要注意的是,不能使用子树高度之差来计算祖先与开始节点的路径长度。例如,E是开始节点,E到B的路径长度为d(E) - d(B) = 2 - 1 = 1,而如果使用子树高度相减的话就得到了h(B) - h(E) = 3 - 0 = 3。
A
/ \
B C
/ \
D E
|
F
|
G在具体实现的时候如何判断祖先节点的哪个子树包含开始节点困扰了我半天。刚开始我选择了一个标志位,分别在左右子树递归结束的时候检测该标志,发现找到之后立即重置该标志,这样父节点就知道了是左子树还是右子树包含开始节点。但问题是再向上返回的时候就无法判断了。
可以考虑返回二维数组,也有网友的题解使用返回值的符号来标识是否找到开始节点。
/**
* @date 2024-04-24 8:56
*/
public class AmountOfTime2385 {
int startToParentToLeaf = 0;
int startToLeaf = 0;
int cnt = 0;
public int amountOfTime(TreeNode root, int start) {
dfs(root, start);
return Math.max(startToLeaf, startToParentToLeaf);
}
/**
* 返回子树深度
*/
public int[] dfs(TreeNode root, int start) {
if (root == null) {
return new int[]{0, 0};
}
int[] l = dfs(root.left, start);
int[] r = dfs(root.right, start);
boolean lfind = l[1] == 1;
boolean rfind = r[1] == 1;
int max = Math.max(r[0], l[0]);
if (lfind || rfind) {
startToParentToLeaf = Math.max(startToParentToLeaf, l[0] + r[0]);
// 这里的返回值不是max,而是祖先节点到开始节点的路径长度
return new int[]{(lfind ? l[0] : r[0]) + 1, 1};
}
if (root.val == start) {
startToLeaf = max;
// 这里直接返回1,不加max
// 视为将开始节点的左右子树删掉,后面回溯时直接相加左右子树高度即可
return new int[]{1, 1};
}
return new int[]{max + 1, 0};
}
/**
* 返回深度
*/
public int[] dfs_v1(TreeNode root, int start, int depth) {
if (root == null) {
return new int[]{depth - 1, 0};
}
int[] l = dfs_v1(root.left, start, depth + 1);
int[] r = dfs_v1(root.right, start, depth + 1);
boolean lfind = l[1] == 1;
boolean rfind = r[1] == 1;
int max = Math.max(r[0], l[0]);
if (lfind) {
cnt++;
startToParentToLeaf = Math.max(r[0] - depth + cnt, startToParentToLeaf);
}
if (rfind) {
cnt++;
startToParentToLeaf = Math.max(l[0] - depth + cnt, startToParentToLeaf);
}
if (root.val == start) {
startToLeaf = max - depth;
return new int[]{max, 1};
}
return new int[]{max, l[1] + r[1]};
}
}