目标
给你 n 个盒子,每个盒子的格式为 [status, candies, keys, containedBoxes] ,其中:
- 状态字 status[i]:整数,如果 box[i] 是开的,那么是 1 ,否则是 0 。
- 糖果数 candies[i]: 整数,表示 box[i] 中糖果的数目。
- 钥匙 keys[i]:数组,表示你打开 box[i] 后,可以得到一些盒子的钥匙,每个元素分别为该钥匙对应盒子的下标。
- 内含的盒子 containedBoxes[i]:整数,表示放在 box[i] 里的盒子所对应的下标。
给你一个 initialBoxes 数组,表示你现在得到的盒子,你可以获得里面的糖果,也可以用盒子里的钥匙打开新的盒子,还可以继续探索从这个盒子里找到的其他盒子。
请你按照上述规则,返回可以获得糖果的 最大数目 。
示例 1:
输入:status = [1,0,1,0], candies = [7,5,4,100], keys = [[],[],[1],[]], containedBoxes = [[1,2],[3],[],[]], initialBoxes = [0]
输出:16
解释:
一开始你有盒子 0 。你将获得它里面的 7 个糖果和盒子 1 和 2。
盒子 1 目前状态是关闭的,而且你还没有对应它的钥匙。所以你将会打开盒子 2 ,并得到里面的 4 个糖果和盒子 1 的钥匙。
在盒子 1 中,你会获得 5 个糖果和盒子 3 ,但是你没法获得盒子 3 的钥匙所以盒子 3 会保持关闭状态。
你总共可以获得的糖果数目 = 7 + 4 + 5 = 16 个。
示例 2:
输入:status = [1,0,0,0,0,0], candies = [1,1,1,1,1,1], keys = [[1,2,3,4,5],[],[],[],[],[]], containedBoxes = [[1,2,3,4,5],[],[],[],[],[]], initialBoxes = [0]
输出:6
解释:
你一开始拥有盒子 0 。打开它你可以找到盒子 1,2,3,4,5 和它们对应的钥匙。
打开这些盒子,你将获得所有盒子的糖果,所以总糖果数为 6 个。
示例 3:
输入:status = [1,1,1], candies = [100,1,100], keys = [[],[0,2],[]], containedBoxes = [[],[],[]], initialBoxes = [1]
输出:1
示例 4:
输入:status = [1], candies = [100], keys = [[]], containedBoxes = [[]], initialBoxes = []
输出:0
示例 5:
输入:status = [1,1,1], candies = [2,3,2], keys = [[],[],[]], containedBoxes = [[],[],[]], initialBoxes = [2,1,0]
输出:7
说明:
- 1 <= status.length <= 1000
- status.length == candies.length == keys.length == containedBoxes.length == n
- status[i] 要么是 0 要么是 1 。
- 1 <= candies[i] <= 1000
- 0 <= keys[i].length <= status.length
- 0 <= keys[i][j] < status.length
- keys[i] 中的值都是互不相同的。
- 0 <= containedBoxes[i].length <= status.length
- 0 <= containedBoxes[i][j] < status.length
- containedBoxes[i] 中的值都是互不相同的。
- 每个盒子最多被一个盒子包含。
- 0 <= initialBoxes.length <= status.length
- 0 <= initialBoxes[i] < status.length
思路
开始时有一些盒子 initialBoxes 元素值表示盒子下标,盒子的状态用 status 数组表示,0 表示盒子被锁住,1 表示盒子是打开的。盒子中装有糖果、也可能装有其它盒子,或者盒子的钥匙。求能够获得的最大糖果数。
bfs 使用优先队列对盒子状态排序,优先取开着的盒子。将开着的盒子中的盒子放入队列,并且用盒子中的钥匙修改队列中的盒子状态。记录已经开过的盒子,避免重复计数。
代码
/**
* @date 2025-06-03 20:30
*/
public class MaxCandies1298 {
public int maxCandies(int[] status, int[] candies, int[][] keys, int[][] containedBoxes, int[] initialBoxes) {
int n = status.length;
int[][] boxes = new int[n][2];
for (int i = 0; i < n; i++) {
boxes[i] = new int[]{i, status[i]};
}
PriorityQueue<int[]> q = new PriorityQueue<>((a, b) -> b[1] - a[1]);
for (int initialBox : initialBoxes) {
q.offer(boxes[initialBox]);
}
int res = 0;
Set<Integer> visited = new HashSet<>();
while (!q.isEmpty() && q.peek()[1] == 1) {
while (!q.isEmpty() && q.peek()[1] == 1) {
int i = q.poll()[0];
visited.add(i);
res += candies[i];
for (int j : keys[i]) {
boxes[j][1] = 1;
}
for (int j : containedBoxes[i]) {
if (visited.contains(j)) {
continue;
}
q.offer(boxes[j]);
}
}
}
return res;
}
}
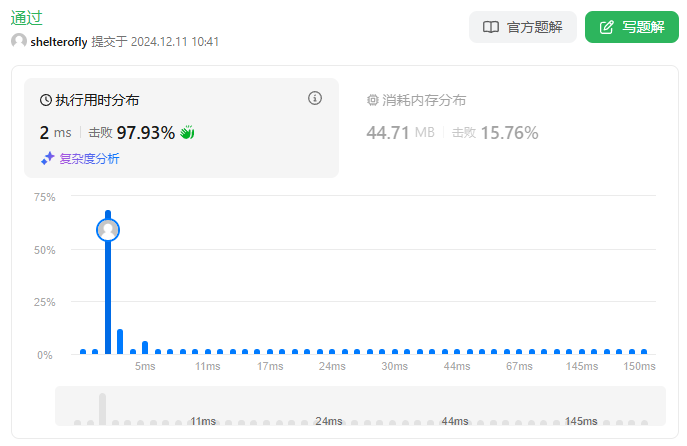
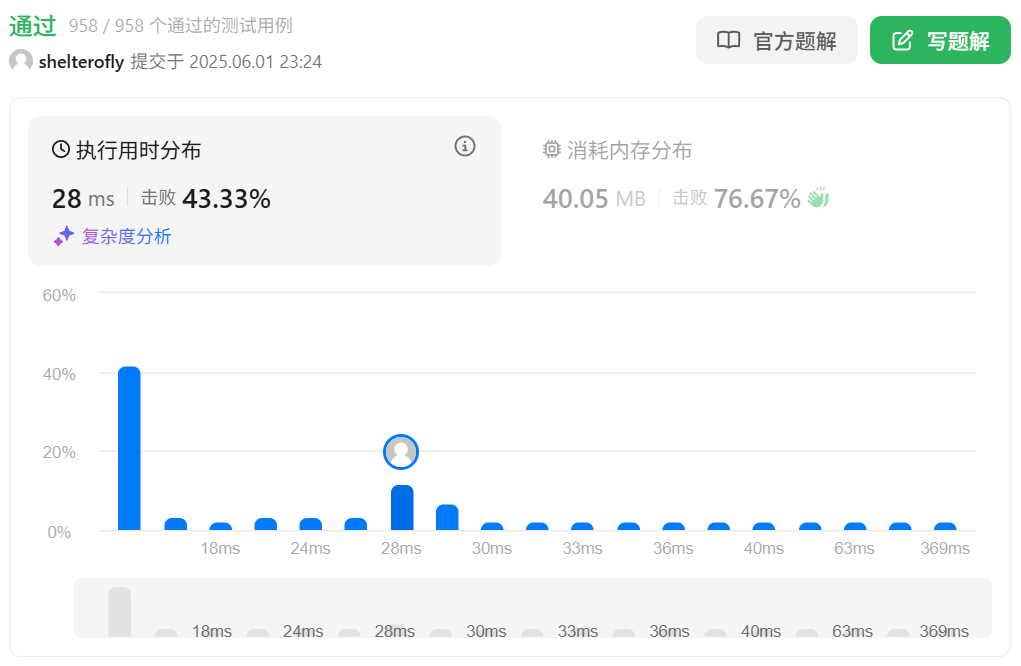
性能