目标
给你一个字符串 date,它的格式为 yyyy-mm-dd,表示一个公历日期。
date 可以重写为二进制表示,只需要将年、月、日分别转换为对应的二进制表示(不带前导零)并遵循 year-month-day 的格式。
返回 date 的 二进制 表示。
示例 1:
输入: date = "2080-02-29"
输出: "100000100000-10-11101"
解释:
100000100000, 10 和 11101 分别是 2080, 02 和 29 的二进制表示。示例 2:
输入: date = "1900-01-01"
输出: "11101101100-1-1"
解释:
11101101100, 1 和 1 分别是 1900, 1 和 1 的二进制表示。说明:
- date.length == 10
- date[4] == date[7] == '-',其余的 date[i] 都是数字。
- 输入保证 date 代表一个有效的公历日期,日期范围从 1900 年 1 月 1 日到 2100 年 12 月 31 日(包括这两天)。
思路
将日期转化为二进制表示。
代码
/**
* @date 2025-01-01 18:53
*/
public class ConvertDateToBinary3280 {
public String convertDateToBinary(String date) {
return new StringBuilder().append(Integer.toBinaryString(Integer.parseInt(date.substring(0,4))))
.append("-")
.append(Integer.toBinaryString(Integer.parseInt(date.substring(5,7))))
.append("-")
.append(Integer.toBinaryString(Integer.parseInt(date.substring(8,10)))).toString();
}
}
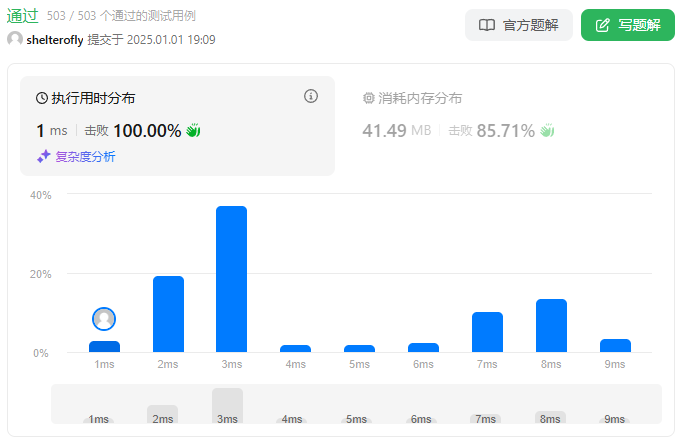
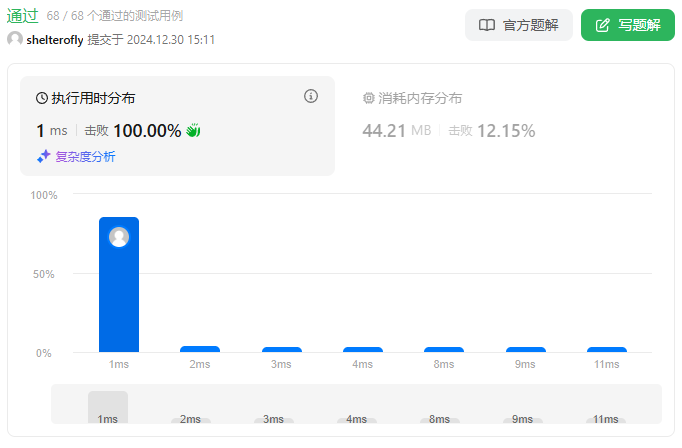
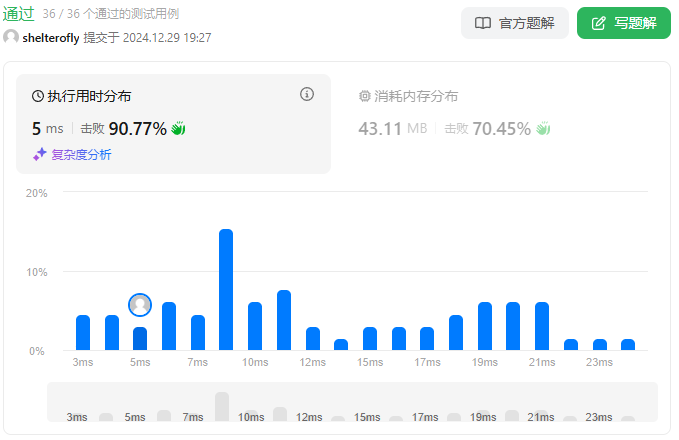
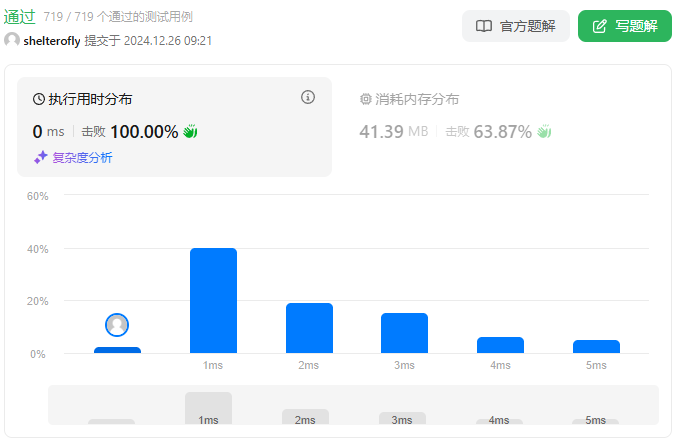
性能