目标
给你一个 m x n 的二进制矩阵 mat ,请你返回有多少个 子矩形 的元素全部都是 1 。
示例 1:
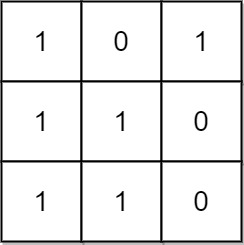
输入:mat = [[1,0,1],[1,1,0],[1,1,0]]
输出:13
解释:
有 6 个 1x1 的矩形。
有 2 个 1x2 的矩形。
有 3 个 2x1 的矩形。
有 1 个 2x2 的矩形。
有 1 个 3x1 的矩形。
矩形数目总共 = 6 + 2 + 3 + 1 + 1 = 13 。示例 2:
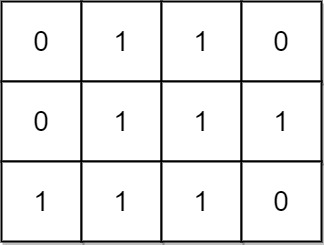
输入:mat = [[0,1,1,0],[0,1,1,1],[1,1,1,0]]
输出:24
解释:
有 8 个 1x1 的子矩形。
有 5 个 1x2 的子矩形。
有 2 个 1x3 的子矩形。
有 4 个 2x1 的子矩形。
有 2 个 2x2 的子矩形。
有 2 个 3x1 的子矩形。
有 1 个 3x2 的子矩形。
矩形数目总共 = 8 + 5 + 2 + 4 + 2 + 2 + 1 = 24 。说明:
- 1 <= m, n <= 150
mat[i][j]仅包含 0 或 1
思路
返回 m x n 矩阵的全 1 子矩阵个数。
枚举行的上下界,计算高度 h,将纵向的 1 压缩到一行,计算全 h 子数组的数目(参考 2348.全0子数组的数目)。
代码
/**
* @date 2025-08-21 8:48
*/
public class NumSubmat1504 {
public int numSubmat(int[][] mat) {
int m = mat.length;
int n = mat[0].length;
int res = 0;
for (int u = 0; u < m; u++) {
for (int l = u; l < m; l++) {
int h = l - u + 1;
int[] row = new int[n];
for (int i = u; i <= l; i++) {
for (int j = 0; j < n; j++) {
row[j] += mat[i][j];
}
}
int p = 0;
while (p < n) {
if (row[p] != h) {
p++;
continue;
}
int start = p;
while (p < n && row[p] == h) {
p++;
}
int cnt = p - start;
res += (cnt + 1) * cnt / 2;
}
}
}
return res;
}
}
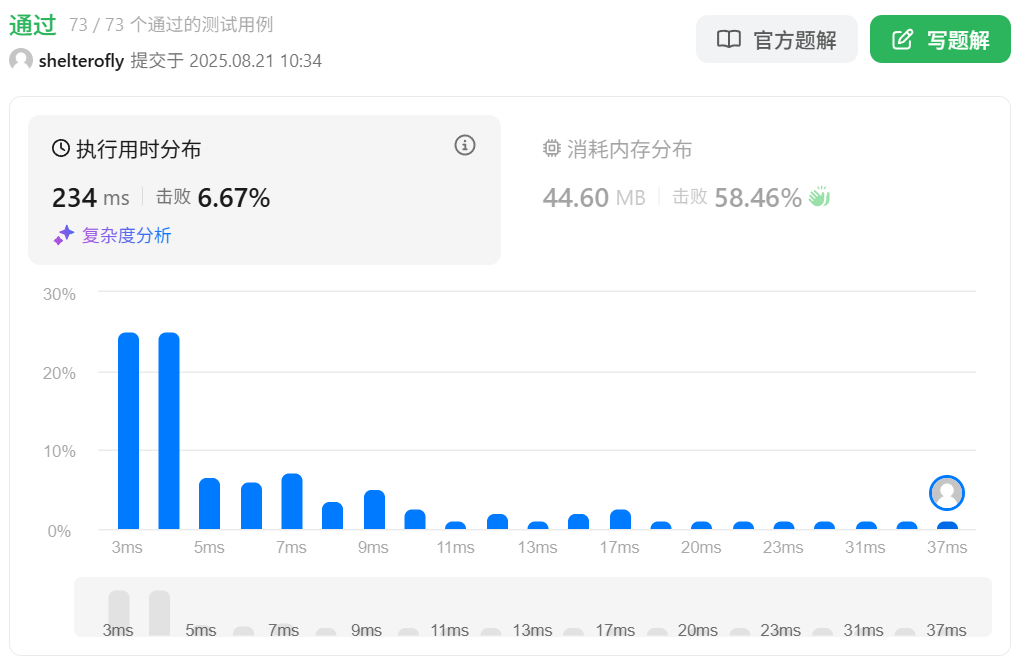
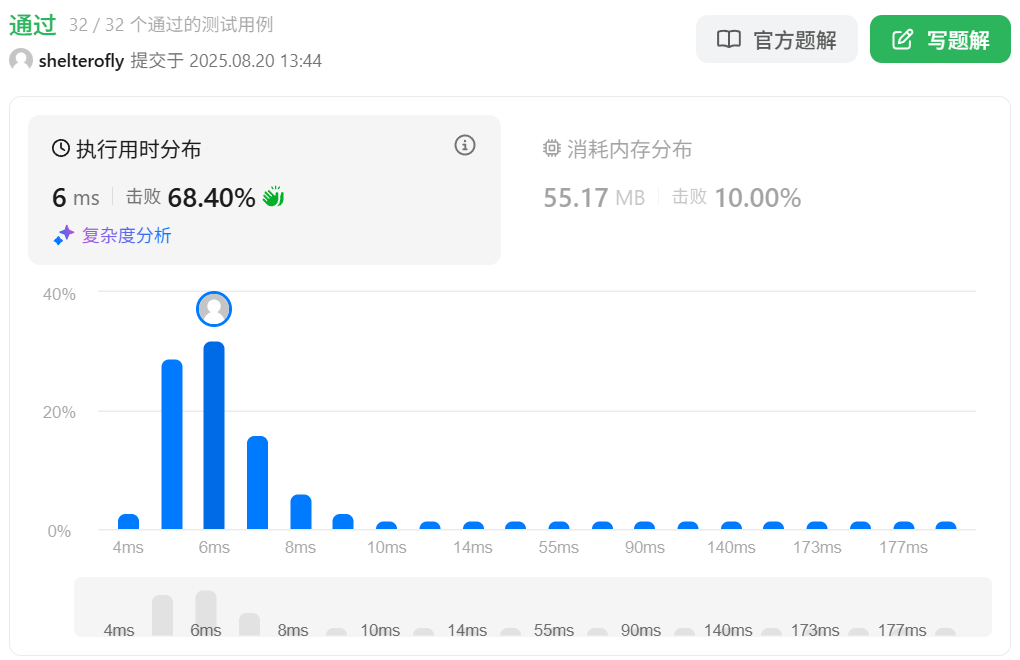
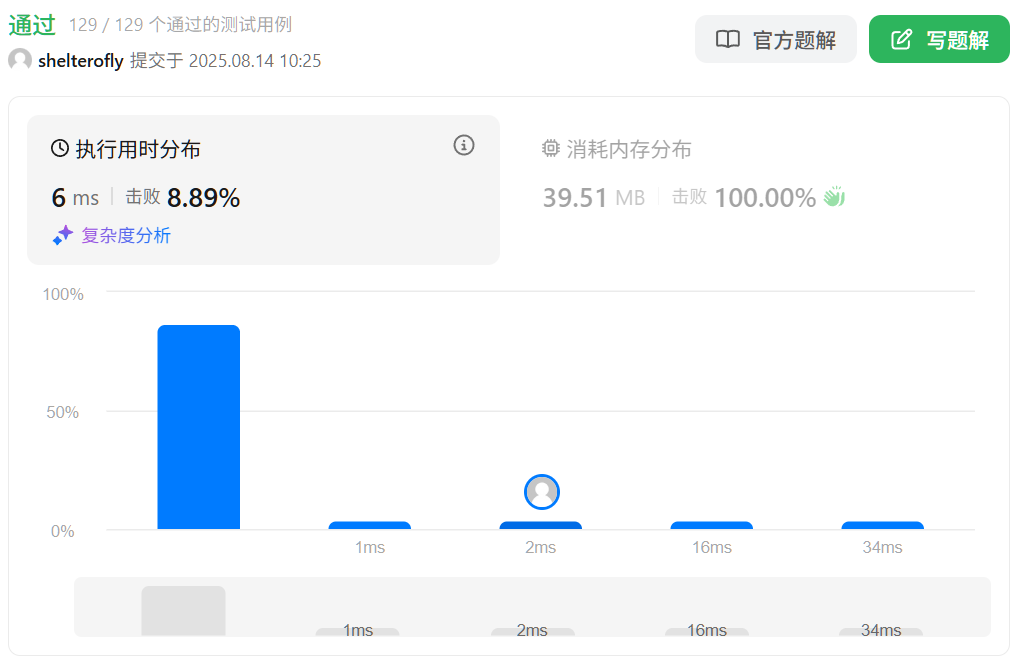
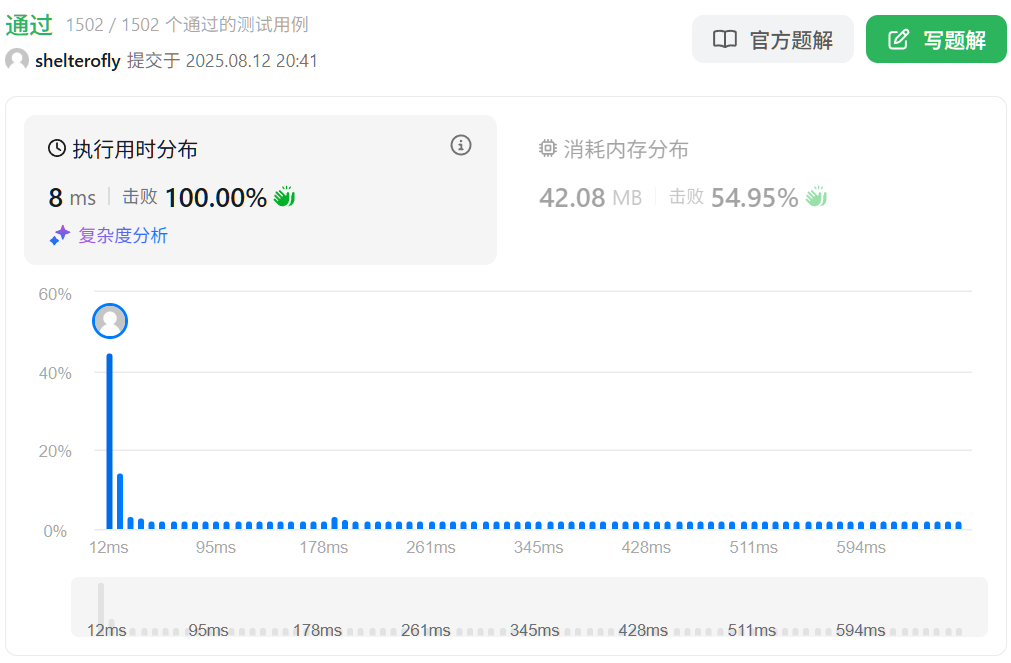
性能