// todo
标签: hard
3098.求出所有子序列的能量和
目标
给你一个长度为 n 的整数数组 nums 和一个 正 整数 k 。
一个 子序列 的 能量 定义为子序列中 任意 两个元素的差值绝对值的 最小值 。
请你返回 nums 中长度 等于 k 的 所有 子序列的 能量和 。
由于答案可能会很大,将答案对 10^9 + 7 取余 后返回。
示例 1:
输入:nums = [1,2,3,4], k = 3
输出:4
解释:
nums 中总共有 4 个长度为 3 的子序列:[1,2,3] ,[1,3,4] ,[1,2,4] 和 [2,3,4] 。能量和为 |2 - 3| + |3 - 4| + |2 - 1| + |3 - 4| = 4 。示例 2:
输入:nums = [2,2], k = 2
输出:0
解释:
nums 中唯一一个长度为 2 的子序列是 [2,2] 。能量和为 |2 - 2| = 0 。示例 3:
输入:nums = [4,3,-1], k = 2
输出:10
解释:
nums 总共有 3 个长度为 2 的子序列:[4,3] ,[4,-1] 和 [3,-1] 。能量和为 |4 - 3| + |4 - (-1)| + |3 - (-1)| = 10 。说明:
- 2 <= n == nums.length <= 50
- -10^8 <= nums[i] <= 10^8
- 2 <= k <= n
思路
定义数组子序列的能量为子序列中任意两个元素差的绝对值的最小值,求数组长度为k的子序列的能量和。
首先思考,数组 nums 长度为n的子序列有多少?根据每一个元素是否在序列中可知有 2^n种可能。n 最大为50,2^50 = 1125899906842624。那么长度为k的子序列有多少? C(n,k) = n!/(k!(n-k)!),当 k=2 时,有 n(n-1)/2 个子序列。
只能考虑动态规划,自底向上地求解。我们可以使用状态压缩来表示子序列,当状态发生转移的时候该如何处理呢?假设我们知道了某k-1子序列的能量,那么再增加一个元素能量会如何变化?比如子序列1,3,6,10,能量为2,再加入一个元素9,能量变为1。还是需要遍历子序列的。那么我们可以根据压缩的状态仅遍历哪些bit位为1的元素。剩下的问题就是如何遍历子序列了。
看了提示,首先要排序,这样差值最小的就两两相邻。刚开始的时候我也在想能不能排序,虽然子序列要保持相对顺序,但本题考虑的是子序列中绝对值差最小的,与顺序无关。
// todo
代码
性能
2959.关闭分部的可行集合数目
目标
一个公司在全国有 n 个分部,它们之间有的有道路连接。一开始,所有分部通过这些道路两两之间互相可以到达。
公司意识到在分部之间旅行花费了太多时间,所以它们决定关闭一些分部(也可能不关闭任何分部),同时保证剩下的分部之间两两互相可以到达且最远距离不超过 maxDistance 。
两个分部之间的 距离 是通过道路长度之和的 最小值 。
给你整数 n ,maxDistance 和下标从 0 开始的二维整数数组 roads ,其中 roads[i] = [ui, vi, wi] 表示一条从 ui 到 vi 长度为 wi的 无向 道路。
请你返回关闭分部的可行方案数目,满足每个方案里剩余分部之间的最远距离不超过 maxDistance。
注意,关闭一个分部后,与之相连的所有道路不可通行。
注意,两个分部之间可能会有多条道路。
示例 1:
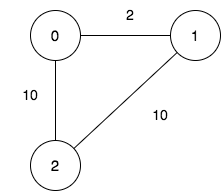
输入:n = 3, maxDistance = 5, roads = [[0,1,2],[1,2,10],[0,2,10]]
输出:5
解释:可行的关闭分部方案有:
- 关闭分部集合 [2] ,剩余分部为 [0,1] ,它们之间的距离为 2 。
- 关闭分部集合 [0,1] ,剩余分部为 [2] 。
- 关闭分部集合 [1,2] ,剩余分部为 [0] 。
- 关闭分部集合 [0,2] ,剩余分部为 [1] 。
- 关闭分部集合 [0,1,2] ,关闭后没有剩余分部。
总共有 5 种可行的关闭方案。示例 2:
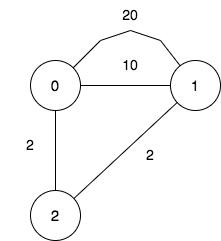
输入:n = 3, maxDistance = 5, roads = [[0,1,20],[0,1,10],[1,2,2],[0,2,2]]
输出:7
解释:可行的关闭分部方案有:
- 关闭分部集合 [] ,剩余分部为 [0,1,2] ,它们之间的最远距离为 4 。
- 关闭分部集合 [0] ,剩余分部为 [1,2] ,它们之间的距离为 2 。
- 关闭分部集合 [1] ,剩余分部为 [0,2] ,它们之间的距离为 2 。
- 关闭分部集合 [0,1] ,剩余分部为 [2] 。
- 关闭分部集合 [1,2] ,剩余分部为 [0] 。
- 关闭分部集合 [0,2] ,剩余分部为 [1] 。
- 关闭分部集合 [0,1,2] ,关闭后没有剩余分部。
总共有 7 种可行的关闭方案。示例 3:
输入:n = 1, maxDistance = 10, roads = []
输出:2
解释:可行的关闭分部方案有:
- 关闭分部集合 [] ,剩余分部为 [0] 。
- 关闭分部集合 [0] ,关闭后没有剩余分部。
总共有 2 种可行的关闭方案。说明:
- 1 <= n <= 10
- 1 <= maxDistance <= 105
- 0 <= roads.length <= 1000
- roads[i].length == 3
- 0 <= ui, vi <= n - 1
- ui != vi
- 1 <= wi <= 1000
- 一开始所有分部之间通过道路互相可以到达。
思路
没时间做了// todo
代码
性能
2972.统计移除递增子数组的数目II
目标
给你一个下标从 0 开始的 正 整数数组 nums 。
如果 nums 的一个子数组满足:移除这个子数组后剩余元素 严格递增 ,那么我们称这个子数组为 移除递增 子数组。比方说,[5, 3, 4, 6, 7] 中的 [3, 4] 是一个移除递增子数组,因为移除该子数组后,[5, 3, 4, 6, 7] 变为 [5, 6, 7] ,是严格递增的。
请你返回 nums 中 移除递增 子数组的总数目。
注意,剩余元素为空的数组也视为是递增的。
子数组 指的是一个数组中一段连续的元素序列。
示例 1:
输入:nums = [1,2,3,4]
输出:10
解释:10 个移除递增子数组分别为:[1], [2], [3], [4], [1,2], [2,3], [3,4], [1,2,3], [2,3,4] 和 [1,2,3,4]。移除任意一个子数组后,剩余元素都是递增的。注意,空数组不是移除递增子数组。示例 2:
输入:nums = [6,5,7,8]
输出:7
解释:7 个移除递增子数组分别为:[5], [6], [5,7], [6,5], [5,7,8], [6,5,7] 和 [6,5,7,8] 。
nums 中只有这 7 个移除递增子数组。示例 3:
输入:nums = [8,7,6,6]
输出:3
解释:3 个移除递增子数组分别为:[8,7,6], [7,6,6] 和 [8,7,6,6] 。注意 [8,7] 不是移除递增子数组因为移除 [8,7] 后 nums 变为 [6,6] ,它不是严格递增的。说明:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^9
思路
有一个正整数数组,如果移除某些子数组可以使得剩余元素严格递增,则称为移除递增子数组。求移除递增子数组的个数。
显然移除递增子数组 [i, j] 后,前后的子数组严格递增,且 nums[i - 1] < nums[j + 1]。我们的目标是要找到有多少种 i, j 的组合满足条件,假设 i ≤ j。
今天又重新思考了一下,可以先求出数组最长的严格递增前缀的最后一个元素之后的下标 first,以及最长的 严格递增后缀第一个元素下标 end。这里下标的含义直接影响着后续的处理,比如这里没有定义end为后缀第一个元素的前一个元素,那么后面遍历的时候j的初值就要取end - 1,因为判断 j == n - 1 时的处理逻辑是排除了所有后缀直接加1,而如果j初值取end,表示nums[j]是被留下来的,就不能简单的加1了,还需要与前面前缀的最后一个元素比较。
- 如果 first 不在数组下标范围内,说明数组整体严格递增,这时所有子数组都满足条件,n 个元素数组的子数组个数为
n * (n + 1) / 2。 - 否则,循环遍历
i ∈[0, first],令j = end - 1,用nums[i - 1]依次与后缀[end, n)范围内的元素比较,如果nums[i - 1] < nums[j + 1]则直接增加n - 1 - (j + 1) + 1 + 1 = n - j个,其中包括[j + 1, n - 1]、……、[n - 1, n - 1] 以及 [0, i),这里省略了与不同前缀的组合(下同)。特别注意:- 当
i == 0时会越界,需要特殊处理。这里剩余的子数组包括:ϕ、[end, n - 1]、[end + 1, n - 1]、……、[n - 1, n - 1],从 end 到n - 1有n - 1 - end + 1 = n - end个,再加上ϕ 即n - end + 1。不能使用公式计算后缀子数组的个数!因为前面存在非严格递增的子数组需要排除掉,而剩余数组是移除递增子数组得到的,前面移除了,后面就必须全部保留,比如[1, 2, 3]的子数组[1] [1,2] [1,2,3] [2] [2,3] [3],我们只能得到[1,2,3] [2,3] [3]再加一个ϕ。 - 当
j = n - 1时会越界,这时表明已经排除了所有后缀,所以直接加1即可,表示前缀子数组[0, i)。
- 当
代码
/**
* @date 2024-07-11 13:12
*/
public class IncremovableSubarrayCount2972 {
public long incremovableSubarrayCount(int[] nums) {
int n = nums.length;
long res = 0;
int first = -1;
int end = -1;
for (int i = 1; i < n; i++) {
if (nums[i] <= nums[i - 1]) {
first = i;
break;
}
}
if (first == -1) {
return n * (n + 1) / 2;
} else {
for (int i = n - 2; i >= 0; i--) {
if (nums[i + 1] <= nums[i]) {
end = i + 1;
break;
}
}
}
for (int i = 0; i <= first; i++) {
if (i == 0) {
res += n - end + 1;
continue;
}
for (int j = end - 1; j < n; j++) {
if (j == n - 1) {
res += 1;
} else if (nums[i - 1] < nums[j + 1]) {
res += n - j;
break;
}
}
}
return res;
}
}
性能
3102.最小化曼哈顿距离
目标
给你一个下标从 0 开始的数组 points ,它表示二维平面上一些点的整数坐标,其中 points[i] = [xi, yi] 。
两点之间的距离定义为它们的 曼哈顿距离。两个单元格 (xi, yi) 和 (xj, yj) 之间的曼哈顿距离为 |xi - xj| + |yi - yj|。
请你恰好移除一个点,返回移除后任意两点之间的 最大 距离可能的 最小 值。
示例 1:
输入:points = [[3,10],[5,15],[10,2],[4,4]]
输出:12
解释:移除每个点后的最大距离如下所示:
- 移除第 0 个点后,最大距离在点 (5, 15) 和 (10, 2) 之间,为 |5 - 10| + |15 - 2| = 18 。
- 移除第 1 个点后,最大距离在点 (3, 10) 和 (10, 2) 之间,为 |3 - 10| + |10 - 2| = 15 。
- 移除第 2 个点后,最大距离在点 (5, 15) 和 (4, 4) 之间,为 |5 - 4| + |15 - 4| = 12 。
- 移除第 3 个点后,最大距离在点 (5, 15) 和 (10, 2) 之间的,为 |5 - 10| + |15 - 2| = 18 。
在恰好移除一个点后,任意两点之间的最大距离可能的最小值是 12 。示例 2:
输入:points = [[1,1],[1,1],[1,1]]
输出:0
解释:移除任一点后,任意两点之间的最大距离都是 0 。说明:
- 3 <= points.length <= 10^5
- points[i].length == 2
1 <= points[i][0], points[i][1] <= 10^8
提示:
- Notice that the Manhattan distance between two points [xi, yi] and [xj, yj] is max({xi - xj + yi - yj, xi - xj - yi + yj, - xi + xj + yi - yj, - xi + xj - yi + yj}).
- If you replace points as [xi - yi, xi + yi] then the Manhattan distance is max(max(xi) - min(xi), max(yi) - min(yi)) over all i.
- After those observations, the problem just becomes a simulation. Create multiset of points [xi - yi, xi + yi], you can iterate on a point you might remove and get the maximum Manhattan distance over all other points.
思路
有一些二维平面上的整数坐标点,移除其中一个点,求任意两点之间曼哈顿距离最大值的最小值。
n个点之间的曼哈顿距离有C(n,2) = n * (n - 1) / 2 个,移除其中一个点,最大值可能发生变化,需要找到其中最小的。
问题的关键是如何计算n个点之间曼哈顿距离的最大值,如果暴力计算,找出最大值的时间复杂度是 O(n^2),还要依次移除一个点找到其中的最小值,综合起来时间复杂度是 O(n^3)。点的个数最多 10^5,暴力求解会超时。
我么需要考虑曼哈顿距离有什么特性,找出最大值需要每一个都遍历吗?移除一个点对最大值有什么影响,需要重新计算吗?
看了题目的提示是使用变量替换将问题转化:两点(xi, yi) 与 (xj, yj) 之间的曼哈顿距离为|xi - xj| + |yi - yj|,去掉绝对值即 max({xi - xj + yi - yj, xi - xj - yi + yj, - xi + xj + yi - yj, - xi + xj - yi + yj}),令 ui = xi - yi, vi = xi + yi,则点 (xi, yi) 与 (xj, yj) 之间的曼哈顿距离转换为 max({vi - vj, ui - uj, uj - ui, vj - vi}) = max({|vi - vj|, |ui- uj|}),对于所有的 i,j,曼哈顿距离的最大值为 max({max(vi) - min(vi), max(ui) - min(ui)})。这样找出曼哈顿距离最大值的时间复杂度减少为 O(n)。
于是,我们只需要将坐标点转化为 (ui, vi),依次去除某个坐标点,再找出 u、v 的最大值与最小值即可。试了一下,O(n^2)的时间复杂度仍会超时。
我们可以记录一下vi、ui取最大最小值时的坐标,然后排除这几个坐标点后找出其中的最小值,最坏的情况即坐标没有重复,时间复杂度为O(4n)。
我也尝试了记录次大与次小值,试图将复杂度降为 O(n),但需要考虑去除掉相应坐标点后,另一个坐标是否会受到影响。例如,max({max(vi) - min(vi), max(ui) - min(ui)}) 假如我们删去了vi最大的坐标,取次大的vi,但是后面ui的最大与最小是否受到影响?
因此我们不仅需要一次遍历获取到最大与次大,还要再次遍历比较当前值是否是最大或最小,如果是则取次大或次小。需要注意,这里的最大与次大以及最小与次小的值可以相同。更进一步,如果我们同时保存了x、y 取最大、最小的四个坐标,我们只需排除这4个坐标即可,其它坐标对最大距离没有影响。
看了官网题解,转换后的距离称为切比雪夫距离。事实上,max({|vi - vj|, |ui - uj|}) 计算的是 (vi, ui) (vj, uj) 两点曼哈顿距离投影到 x 轴(|vi - vj|) 和 y 轴(|ui - uj|)的线段长度的最大值,即切比雪夫距离。注意本题中的u、v对应题解中v、u,并且使用的是x-y,而非y-x,不过对于求解没有什么影响,无非是关于坐标轴镜像了一下。
代码
/**
* @date 2024-07-09 10:20
*/
public class MinimumDistance3102 {
public int minimumDistance(int[][] points) {
for (int[] point : points) {
int u = point[0] - point[1];
int v = point[0] + point[1];
point[0] = u;
point[1] = v;
}
int n = points.length;
int res = Integer.MAX_VALUE;
int maxX = Integer.MIN_VALUE;
int minX = Integer.MAX_VALUE;
int maxY = Integer.MIN_VALUE;
int minY = Integer.MAX_VALUE;
int maxXIndex = -1, minXIndex = -1, maxYIndex = -1, minYIndex = -1;
List<Integer> exclude = new ArrayList<>();
for (int j = 0; j < n; j++) {
if (points[j][0] > maxX) {
maxX = points[j][0];
maxXIndex = j;
}
if (points[j][0] < minX) {
minX = points[j][0];
minXIndex = j;
}
if (points[j][1] > maxY) {
maxY = points[j][1];
maxYIndex = j;
}
if (points[j][1] < minY) {
minY = points[j][1];
minYIndex = j;
}
}
exclude.add(maxXIndex);
exclude.add(minXIndex);
exclude.add(maxYIndex);
exclude.add(minYIndex);
for (Integer i : exclude) {
maxX = Integer.MIN_VALUE;
minX = Integer.MAX_VALUE;
maxY = Integer.MIN_VALUE;
minY = Integer.MAX_VALUE;
for (int j = 0; j < n; j++) {
if (i != j) {
maxX = Math.max(maxX, points[j][0]);
minX = Math.min(minX, points[j][0]);
maxY = Math.max(maxY, points[j][1]);
minY = Math.min(minY, points[j][1]);
}
}
res = Math.min(res, Math.max(maxX - minX, maxY - minY));
}
return res;
}
}
性能

3086.拾起K个1需要的最少行动次数
目标
给你一个下标从 0 开始的二进制数组 nums,其长度为 n ;另给你一个 正整数 k 以及一个 非负整数 maxChanges 。
Alice 在玩一个游戏,游戏的目标是让 Alice 使用 最少 数量的 行动 次数从 nums 中拾起 k 个 1 。游戏开始时,Alice 可以选择数组 [0, n - 1] 范围内的任何索引 aliceIndex 站立。如果 nums[aliceIndex] == 1 ,Alice 会拾起一个 1 ,并且 nums[aliceIndex] 变成0(这 不算 作一次行动)。之后,Alice 可以执行 任意数量 的 行动(包括零次),在每次行动中 Alice 必须 恰好 执行以下动作之一:
- 选择任意一个下标 j != aliceIndex 且满足 nums[j] == 0 ,然后将 nums[j] 设置为 1 。这个动作最多可以执行 maxChanges 次。
- 选择任意两个相邻的下标 x 和 y(|x - y| == 1)且满足 nums[x] == 1, nums[y] == 0 ,然后交换它们的值(将 nums[y] = 1 和 nums[x] = 0)。如果 y == aliceIndex,在这次行动后 Alice 拾起一个 1 ,并且 nums[y] 变成 0 。
返回 Alice 拾起 恰好 k 个 1 所需的 最少 行动次数。
示例 1:
输入:nums = [1,1,0,0,0,1,1,0,0,1], k = 3, maxChanges = 1
输出:3
解释:如果游戏开始时 Alice 在 aliceIndex == 1 的位置上,按照以下步骤执行每个动作,他可以利用 3 次行动拾取 3 个 1 :
游戏开始时 Alice 拾取了一个 1 ,nums[1] 变成了 0。此时 nums 变为 [1,0,0,0,0,1,1,0,0,1] 。
选择 j == 2 并执行第一种类型的动作。nums 变为 [1,0,1,0,0,1,1,0,0,1]
选择 x == 2 和 y == 1 ,并执行第二种类型的动作。nums 变为 [1,1,0,0,0,1,1,0,0,1] 。由于 y == aliceIndex,Alice 拾取了一个 1 ,nums 变为 [1,0,0,0,0,1,1,0,0,1] 。
选择 x == 0 和 y == 1 ,并执行第二种类型的动作。nums 变为 [0,1,0,0,0,1,1,0,0,1] 。由于 y == aliceIndex,Alice 拾取了一个 1 ,nums 变为 [0,0,0,0,0,1,1,0,0,1] 。
请注意,Alice 也可能执行其他的 3 次行动序列达成拾取 3 个 1 。示例 2:
输入:nums = [0,0,0,0], k = 2, maxChanges = 3
输出:4
解释:如果游戏开始时 Alice 在 aliceIndex == 0 的位置上,按照以下步骤执行每个动作,他可以利用 4 次行动拾取 2 个 1 :
选择 j == 1 并执行第一种类型的动作。nums 变为 [0,1,0,0] 。
选择 x == 1 和 y == 0 ,并执行第二种类型的动作。nums 变为 [1,0,0,0] 。由于 y == aliceIndex,Alice 拾起了一个 1 ,nums 变为 [0,0,0,0] 。
再次选择 j == 1 并执行第一种类型的动作。nums 变为 [0,1,0,0] 。
再次选择 x == 1 和 y == 0 ,并执行第二种类型的动作。nums 变为 [1,0,0,0] 。由于y == aliceIndex,Alice 拾起了一个 1 ,nums 变为 [0,0,0,0] 。说明:
- 2 <= n <= 10^5
- 0 <= nums[i] <= 1
- 1 <= k <= 10^5
- 0 <= maxChanges <= 10^5
- maxChanges + sum(nums) >= k
思路
有一个二进制(元素不是0就是1)数组nums,选择一个固定的位置aliceIndex,如果该位置元素值为1,则可以拾起并将元素置0。接下来可以采取行动:
- 任选一个不等于aliceIndex且值为0的元素置1
- 将任意相邻且元素值不等的元素交换,如果其中一个位置是aliceIndex,且交换后的值为1,则可以拾起这个1并将元素置0
问恰好拾起k个1所需最小行动次数。
很明显行动1要选与aliceIndex相邻的,这样才可以用行动2将1拾起。
我们首先面对的问题是aliceIndex怎么选,要拾取1就需要将1都通过行动2移动到aliceIndex周围,如果拾取一个1的行动次数大于2的话就需要考虑使用行动1直接在aliceIndex周围设置1再拾取。
// todo
代码
性能
2065.最大化一张图中的路径价值
// todo
2742.给墙壁刷油漆
// todo
2732.找到矩阵中的好子集
目标
给你一个下标从 0 开始大小为 m x n 的二进制矩阵 grid 。
从原矩阵中选出若干行构成一个行的 非空 子集,如果子集中任何一列的和至多为子集大小的一半,那么我们称这个子集是 好子集。
更正式的,如果选出来的行子集大小(即行的数量)为 k,那么每一列的和至多为 floor(k / 2) 。
请你返回一个整数数组,它包含好子集的行下标,请你将子集中的元素 升序 返回。
如果有多个好子集,你可以返回任意一个。如果没有好子集,请你返回一个空数组。
一个矩阵 grid 的行 子集 ,是删除 grid 中某些(也可能不删除)行后,剩余行构成的元素集合。
示例 1:
输入:grid = [[0,1,1,0],[0,0,0,1],[1,1,1,1]]
输出:[0,1]
解释:我们可以选择第 0 和第 1 行构成一个好子集。
选出来的子集大小为 2 。
- 第 0 列的和为 0 + 0 = 0 ,小于等于子集大小的一半。
- 第 1 列的和为 1 + 0 = 1 ,小于等于子集大小的一半。
- 第 2 列的和为 1 + 0 = 1 ,小于等于子集大小的一半。
- 第 3 列的和为 0 + 1 = 1 ,小于等于子集大小的一半。示例 2:
输入:grid = [[0]]
输出:[0]
解释:我们可以选择第 0 行构成一个好子集。
选出来的子集大小为 1 。
- 第 0 列的和为 0 ,小于等于子集大小的一半。示例 3:
输入:grid = [[1,1,1],[1,1,1]]
输出:[]
解释:没有办法得到一个好子集。说明:
- m == grid.length
- n == grid[i].length
- 1 <= m <= 10^4
- 1 <= n <= 5
grid[i][j]要么是 0 ,要么是 1 。
思路
有一个 m*n 的 二进制矩阵,任选k行,如果每一列的和不大于 k/2,则称为矩阵的好子集,返回任意一个好子集行标的集合。
在写这篇题解的时候才注意到是二进制矩阵,即元素值不是0就是1。这道题是根据提示写的,如果存在好子集则一定存在k为1或2的好子集,然后就根据好子集的要求循环判断。
当k为1时,好子集元素值全为0.当k为2时,任选两行遍历列判断是否有和大于1。
// todo 看一下题解
代码
/**
* @date 2024-06-25 0:28
*/
public class GoodSubsetofBinaryMatrix2732 {
public List<Integer> goodSubsetofBinaryMatrix(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
List<Integer> list = new ArrayList<>();
Queue<Integer> queue = new ArrayDeque<>();
here:
for (int i = 0; i < m; i++) {
queue.offer(i);
for (int j = 0; j < n; j++) {
if (grid[i][j] != 0) {
continue here;
}
}
list.add(i);
}
if (list.size() > 0) {
return list;
}
while (!queue.isEmpty()) {
int i = queue.poll();
here:
for (int j = i + 1; j < m; j++) {
for (int k = 0; k < n; k++) {
if (grid[i][k] + grid[j][k] > 1){
continue here;
}
}
list.add(i);
list.add(j);
return list;
}
}
return list;
}
}
性能
2713.矩阵中严格递增的单元格数
目标
给你一个下标从 1 开始、大小为 m x n 的整数矩阵 mat,你可以选择任一单元格作为 起始单元格 。
从起始单元格出发,你可以移动到 同一行或同一列 中的任何其他单元格,但前提是目标单元格的值 严格大于 当前单元格的值。
你可以多次重复这一过程,从一个单元格移动到另一个单元格,直到无法再进行任何移动。
请你找出从某个单元开始访问矩阵所能访问的 单元格的最大数量 。
返回一个表示可访问单元格最大数量的整数。
示例 1:
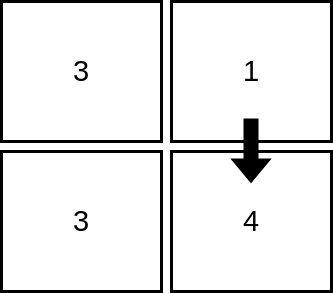
输入:mat = [[3,1],[3,4]]
输出:2
解释:上图展示了从第 1 行、第 2 列的单元格开始,可以访问 2 个单元格。可以证明,无论从哪个单元格开始,最多只能访问 2 个单元格,因此答案是 2 。示例 2:
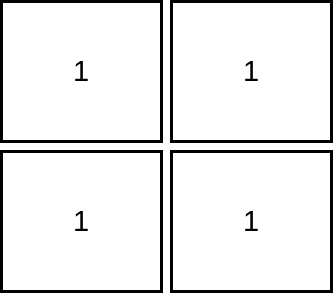
输入:mat = [[1,1],[1,1]]
输出:1
解释:由于目标单元格必须严格大于当前单元格,在本示例中只能访问 1 个单元格。 示例 3:
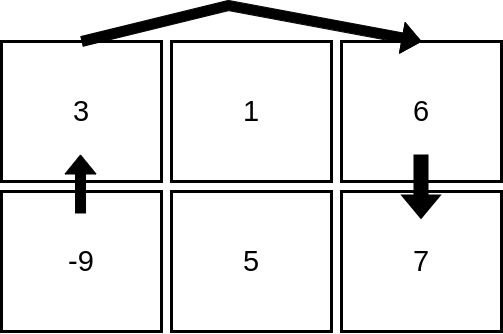
输入:mat = [[3,1,6],[-9,5,7]]
输出:4
解释:上图展示了从第 2 行、第 1 列的单元格开始,可以访问 4 个单元格。可以证明,无论从哪个单元格开始,最多只能访问 4 个单元格,因此答案是 4 。 说明:
- m == mat.length
- n == mat[i].length
- 1 <= m, n <= 10^5
- 1 <= m * n <= 10^5
-10^5 <= mat[i][j] <= 10^5
思路
有一个二维矩阵,我们可以从任意元素出发到达同行或同列的任意严格大于该元素值的位置,问我们最多能访问到多少单元格。
最直接的想法就是建立一个有向无环图,然后求最大路径长度。但是建图的过程需要循环mn(m+n)次,针对每个元素判断其同行同列上严格大于的元素。显然会超时。
于是考虑使用记忆化搜索,结果测试用例 558/566 超时,这个二维数组只有一行,有 100000列,从 1~100000,我在本地测试的时候报栈溢出。
我想要将其转为迭代的形式,但是时间紧迫,简单起见对一行或一列的情况做了特殊处理,排序后去重,最后勉强通过了。
官网题解使用的是动态规划,有时间详细看一下。//todo
代码
/**
* @date 2024-06-19 16:28
*/
public class MaxIncreasingCells2713 {
public int maxIncreasingCells(int[][] mat) {
int res = 0;
int m = mat.length;
int n = mat[0].length;
if (m == 1) {
res = n;
Arrays.sort(mat[0]);
for (int i = 1; i < n; i++) {
if (mat[0][i] == mat[0][i - 1]) {
res--;
}
}
return res;
} else if (n == 1) {
res = m;
Arrays.sort(mat, (a, b) -> a[0] - b[0]);
for (int i = 1; i < m; i++) {
if (mat[i][0] == mat[i - 1][0]) {
res--;
}
}
return res;
}
int l = m * n;
// 将二维坐标映射到一维,dp记录的是从该点为起点的能移动的最大次数
int[] dp = new int[l];
Arrays.fill(dp, -1);
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
res = Math.max(res, move(mat, mat[i][j], i * n + j, i, j, dp));
}
}
return res;
}
public int move(int[][] mat, int curVal, int next, int i, int j, int[] dp) {
int m = mat.length;
int n = mat[0].length;
if (dp[next] > -1) {
return dp[next];
} else if (dp[next] == -2) {
return 1;
}
boolean noNext = true;
for (int k = 0; k < n; k++) {
if (mat[i][k] > curVal) {
noNext = false;
dp[next] = Math.max(dp[next], move(mat, mat[i][k], i * n + k, i, k, dp) + 1);
}
}
for (int k = 0; k < m; k++) {
if (mat[k][j] > curVal) {
noNext = false;
dp[next] = Math.max(dp[next], move(mat, mat[k][j], k * n + j, k, j, dp) + 1);
}
}
if (noNext) {
dp[next] = -2;
return 1;
}
return dp[next];
}
}
性能
