目标
你有 n 个机器人,给你两个下标从 0 开始的整数数组 chargeTimes 和 runningCosts ,两者长度都为 n 。第 i 个机器人充电时间为 chargeTimes[i] 单位时间,花费 runningCosts[i] 单位时间运行。再给你一个整数 budget 。
运行 k 个机器人 总开销 是 max(chargeTimes) + k * sum(runningCosts) ,其中 max(chargeTimes) 是这 k 个机器人中最大充电时间,sum(runningCosts) 是这 k 个机器人的运行时间之和。
请你返回在 不超过 budget 的前提下,你 最多 可以 连续 运行的机器人数目为多少。
示例 1:
输入:chargeTimes = [3,6,1,3,4], runningCosts = [2,1,3,4,5], budget = 25
输出:3
解释:
可以在 budget 以内运行所有单个机器人或者连续运行 2 个机器人。
选择前 3 个机器人,可以得到答案最大值 3 。总开销是 max(3,6,1) + 3 * sum(2,1,3) = 6 + 3 * 6 = 24 ,小于 25 。
可以看出无法在 budget 以内连续运行超过 3 个机器人,所以我们返回 3 。示例 2:
输入:chargeTimes = [11,12,19], runningCosts = [10,8,7], budget = 19
输出:0
解释:即使运行任何一个单个机器人,还是会超出 budget,所以我们返回 0 。说明:
- chargeTimes.length == runningCosts.length == n
- 1 <= n <= 5 * 10^4
- 1 <= chargeTimes[i], runningCosts[i] <= 10^5
- 1 <= budget <= 10^15
思路
选择连续的 k 个机器人,使开销不超过预算 budget。其中机器人的开销等于其中 所选机器人的最长的充电时间 + k * 所选k个机器人花费之和。
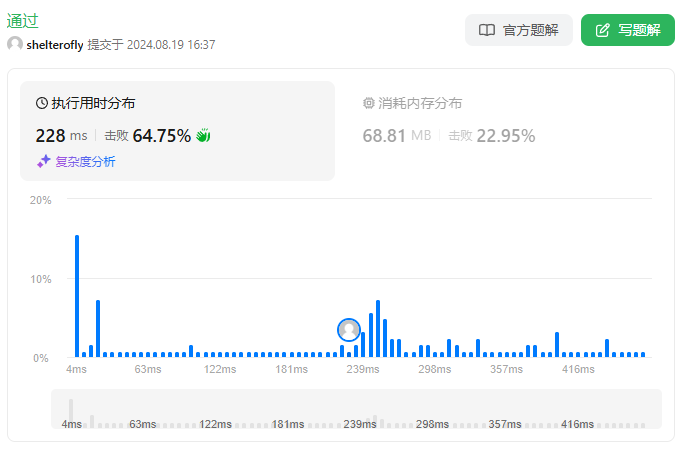
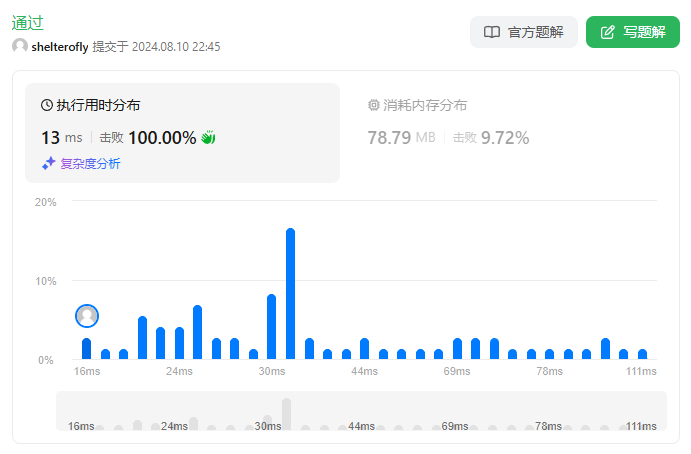
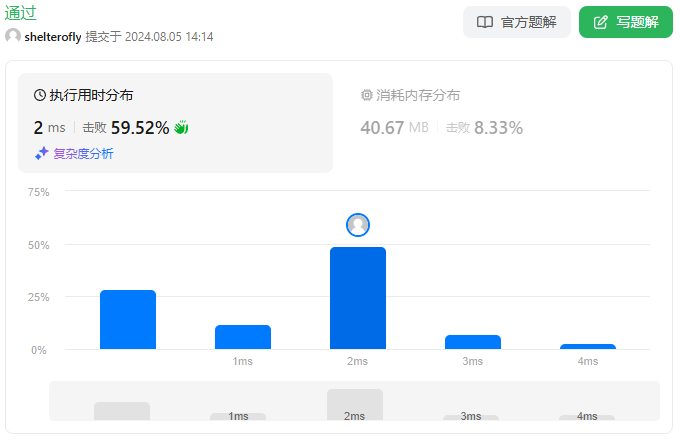
直接的想法是二分查找 k,然后使用滑动窗口记录最小的开销 min,如果 min < budget 增大 k,否则减小 k。时间复杂度为 O(nlogn)。
核心点在于滑动窗口的时候 max(chargeTimes) 如何更新。今天又解锁了新词条:单调队列。
// todo
代码