目标
给你一个长度为 n 的整数数组 nums。
三段式子数组 是一个连续子数组 nums[l...r](满足 0 <= l < r < n),并且存在下标 l < p < q < r,使得:
- nums[l...p] 严格 递增,
- nums[p...q] 严格 递减,
- nums[q...r] 严格 递增。
请你从数组 nums 的所有三段式子数组中找出和最大的那个,并返回其 最大 和。
示例 1:
输入:nums = [0,-2,-1,-3,0,2,-1]
输出:-4
解释:
选择 l = 1, p = 2, q = 3, r = 5:
nums[l...p] = nums[1...2] = [-2, -1] 严格递增 (-2 < -1)。
nums[p...q] = nums[2...3] = [-1, -3] 严格递减 (-1 > -3)。
nums[q...r] = nums[3...5] = [-3, 0, 2] 严格递增 (-3 < 0 < 2)。
和 = (-2) + (-1) + (-3) + 0 + 2 = -4。示例 2:
输入: nums = [1,4,2,7]
输出: 14
解释:
选择 l = 0, p = 1, q = 2, r = 3:
nums[l...p] = nums[0...1] = [1, 4] 严格递增 (1 < 4)。
nums[p...q] = nums[1...2] = [4, 2] 严格递减 (4 > 2)。
nums[q...r] = nums[2...3] = [2, 7] 严格递增 (2 < 7)。
和 = 1 + 4 + 2 + 7 = 14。说明:
- 4 <= n = nums.length <= 10^5
- -10^9 <= nums[i] <= 10^9
- 保证至少存在一个三段式子数组。
思路
3637.三段式数组I 判断是否是三段式数组,本题则是计算数组的三段式子数组的最大和。
定义 dp[k][i] 表示第 k 段以 i 结尾的前 k 段子数组的最大和,其中 k ∈ [0.2]。由于每一段至少有两个元素,如果 i - 1 是该段的起始,根据前面的定义,应该属于 k - 1 段。因此有 dp[k][i] = Math.max(dp[k - 1][i - 1], dp[k][i - 1]) + nums[i],当 k = 0 时,将 dp[k - 1][i - 1] 替换为 nums[i - 1] 即可。如果处于严格递增段,可以是第一段或第三段,如果处于严格递减段,则只能是第二段。
代码
/**
* @date 2026-02-04 8:57
*/
public class MaxSumTrionic3640 {
public long maxSumTrionic(int[] nums) {
int n = nums.length;
long[][] dp = new long[3][n];
for (int k = 0; k < 3; k++) {
Arrays.fill(dp[k], Long.MIN_VALUE / 2);
}
long res = Long.MIN_VALUE / 2;
for (int i = 1; i < n; i++) {
if (nums[i] > nums[i - 1]) {
dp[0][i] = Math.max(nums[i - 1], dp[0][i - 1]) + nums[i];
dp[2][i] = Math.max(dp[1][i - 1], dp[2][i - 1]) + nums[i];
} else if (nums[i] < nums[i - 1]) {
dp[1][i] = Math.max(dp[0][i - 1], dp[1][i - 1]) + nums[i];
}
res = Math.max(res, dp[2][i]);
}
return res;
}
}
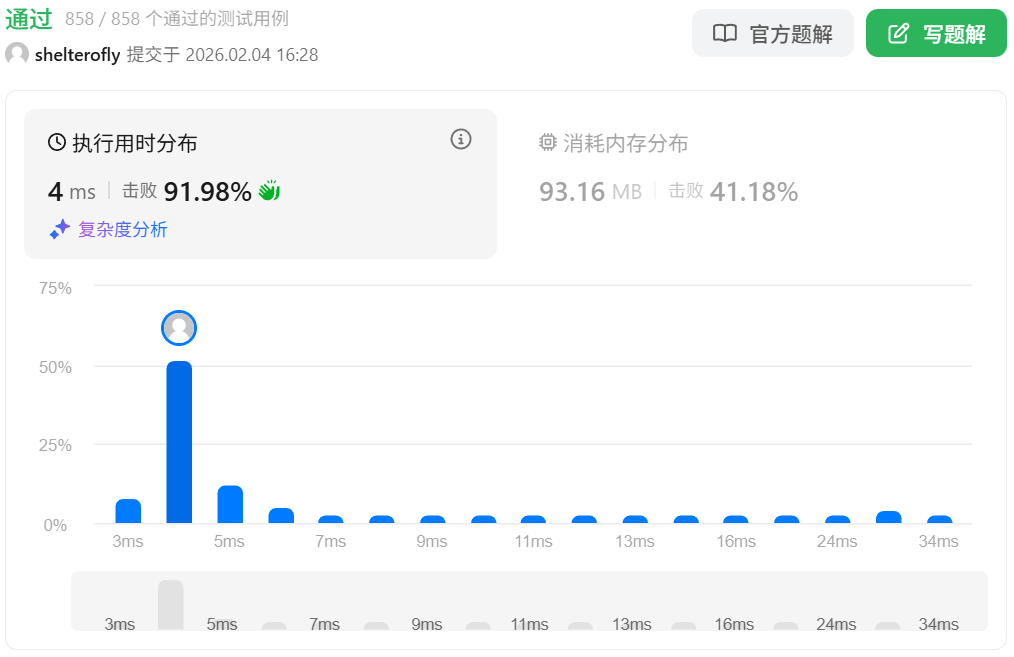
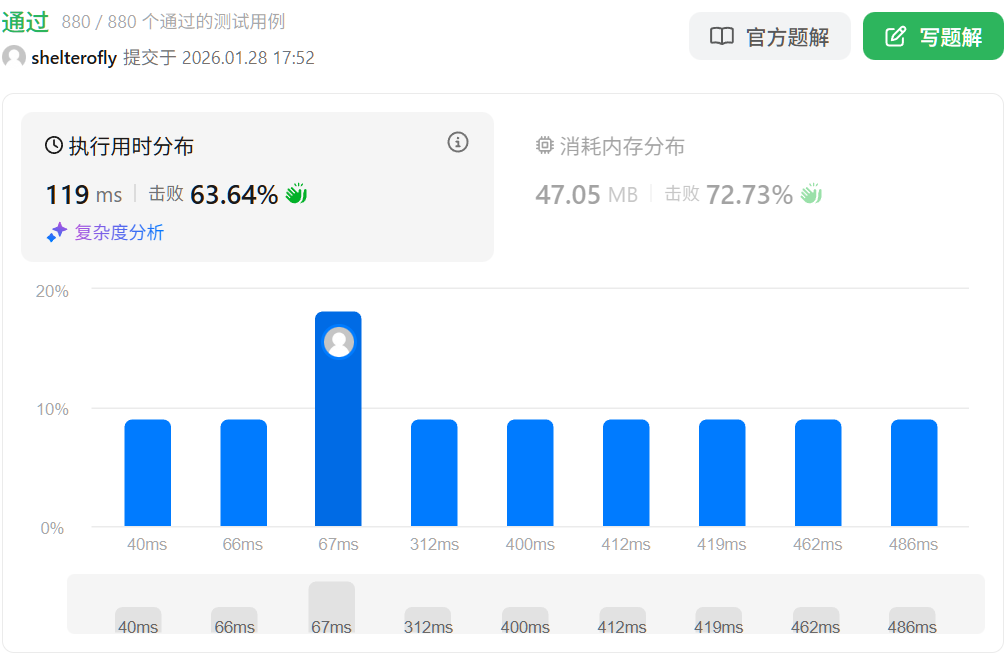
性能