目标
给你一个正整数数组 nums 。
- 元素和 是 nums 中的所有元素相加求和。
- 数字和 是 nums 中每一个元素的每一数位(重复数位需多次求和)相加求和。
返回 元素和 与 数字和 的绝对差。
注意:两个整数 x 和 y 的绝对差定义为 |x - y| 。
示例 1:
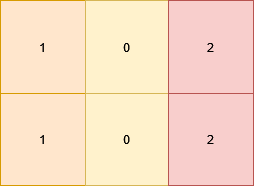
输入:nums = [1,15,6,3]
输出:9
解释:
nums 的元素和是 1 + 15 + 6 + 3 = 25 。
nums 的数字和是 1 + 1 + 5 + 6 + 3 = 16 。
元素和与数字和的绝对差是 |25 - 16| = 9 。示例 2:
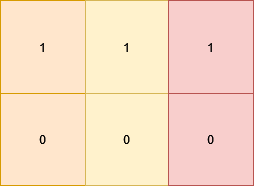
输入:nums = [1,2,3,4]
输出:0
解释:
nums 的元素和是 1 + 2 + 3 + 4 = 10 。
nums 的数字和是 1 + 2 + 3 + 4 = 10 。
元素和与数字和的绝对差是 |10 - 10| = 0 。说明:
- 1 <= nums.length <= 2000
- 1 <= nums[i] <= 2000
思路
直接根据题意计算即可。由于元素和一定大于数字和,不用分开计算。
代码
/**
* @date 2024-09-26 8:45
*/
public class DifferenceOfSum2535 {
public int differenceOfSum(int[] nums) {
int res = 0;
for (int num : nums) {
res += num;
while (num > 0) {
res -= num % 10;
num /= 10;
}
}
return res;
}
}
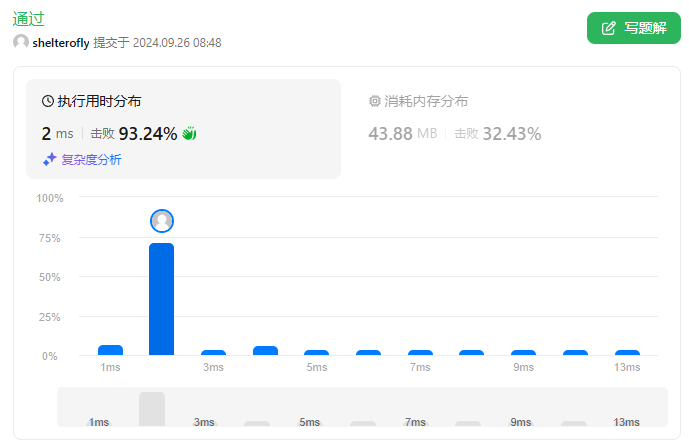
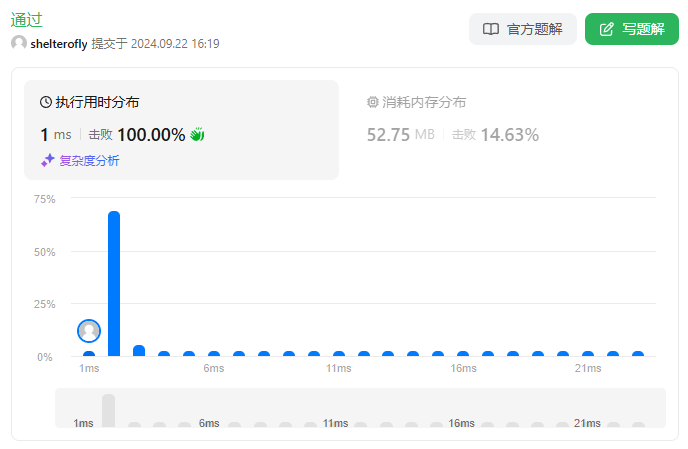
性能