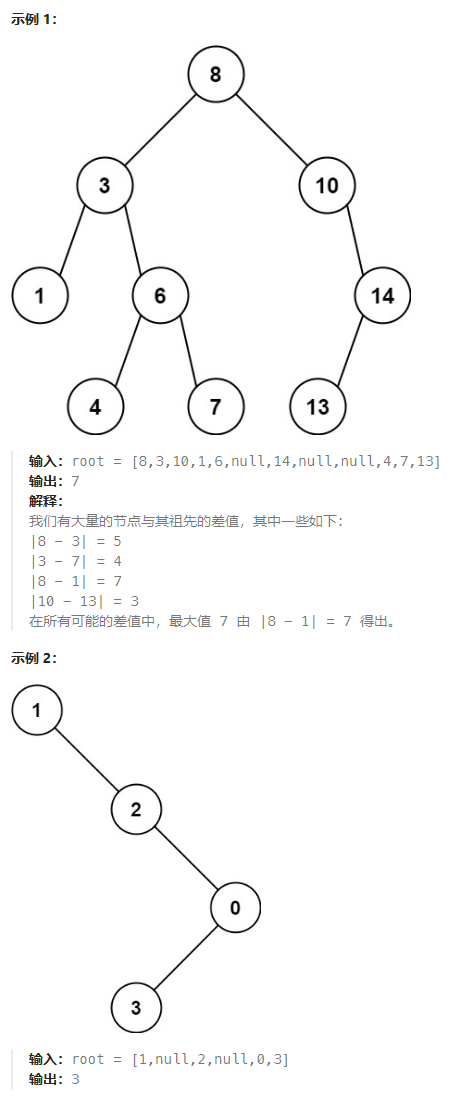
目标
给你一个 n 个节点的树(也就是一个无环连通无向图),节点编号从 0 到 n - 1 ,且恰好有 n - 1 条边,每个节点有一个值。树的 根节点 为 0 号点。
给你一个整数数组 nums 和一个二维数组 edges 来表示这棵树。nums[i] 表示第 i 个点的值,edges[j] = [uj, vj] 表示节点 uj 和节点 vj 在树中有一条边。
当 gcd(x, y) == 1 ,我们称两个数 x 和 y 是 互质的 ,其中 gcd(x, y) 是 x 和 y 的 最大公约数 。
从节点 i 到 根 最短路径上的点都是节点 i 的祖先节点。一个节点 不是 它自己的祖先节点。
请你返回一个大小为 n 的数组 ans ,其中 ans[i]是离节点 i 最近的祖先节点且满足 nums[i] 和 nums[ans[i]] 是 互质的 ,如果不存在这样的祖先节点,ans[i] 为 -1 。
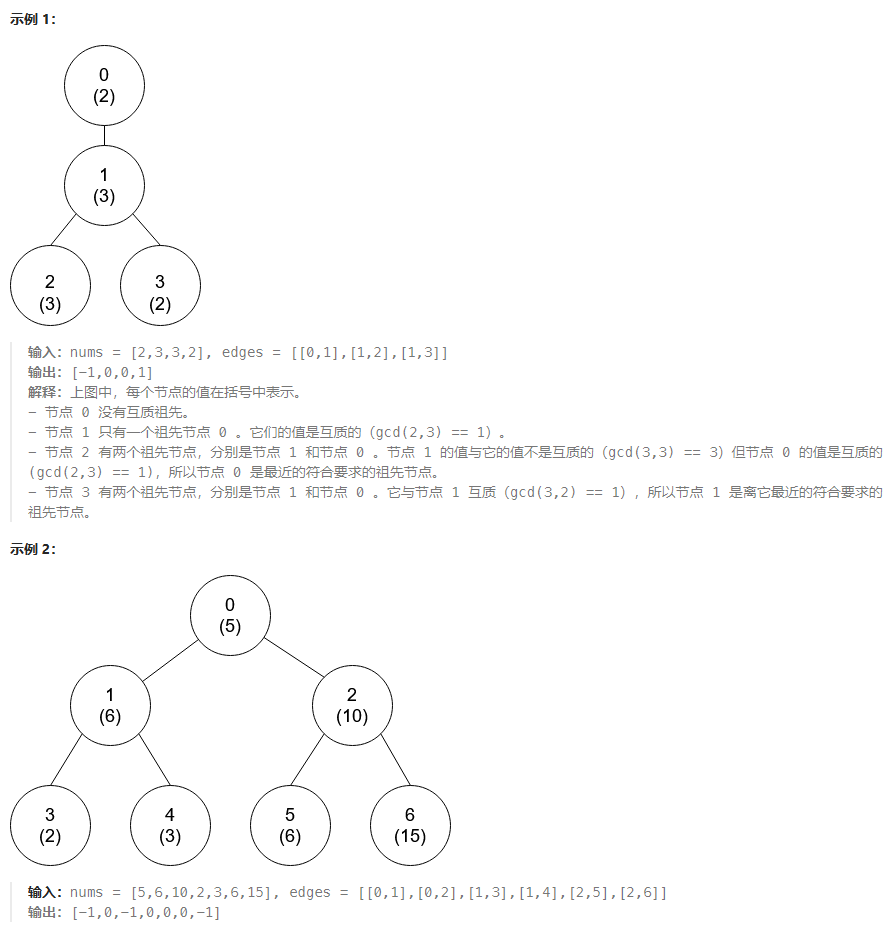
说明:
- nums.length == n
- 1 <= nums[i] <= 50
- 1 <= n <= 10^5
- edges.length == n - 1
- edges[j].length == 2
- 0 <= uj, vj < n
- uj != vj
思路
今天这道题超时了,看了答案才发现节点值不超过50。没有注意到这个点,答案是先计算1到50内每个数字互质的数字列表。然后在dfs的时候记录节点值的最大深度,以及最近的编号。
我是直接记录了parent数组,一步一步向上找,在第35/37个案例超时了,这棵树是单链,并且除了根节点,向上找都不互质,只能从叶子找到根。
这样在递归中套递归直接堆栈溢出了。后来又将这两个递归分开,不溢出了,但还是超时。
后来又试图利用已求得的结果,记录了value -> 最近互质父节点编号的映射,错误地认为如果值相等就可以直接返回这个编号。其实是不对的,因为这二者之间的父节点也可能与当前节点互质。
其实我想到了应该维护一个去重的父节点序列,但是今天没时间了,只能去看答案了。预处理这个点没有想到,记录值的最大深度与最近编号这个也不好想,也许时间充裕可能会想到吧。
好多经过深度思考得到的复杂的算法,时间久了就会忘记许多细节。没必要非得自己想出来,有这时间多看看算法书进步的更快吧。
代码
// todo
性能
// todo