目标
给你一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] = [li, ri, vali]。
每个 queries[i] 表示在 nums 上执行以下操作:
- 将 nums 中 [li, ri] 范围内的每个下标对应元素的值 最多 减少 vali。
- 每个下标的减少的数值可以独立选择。
零数组 是指所有元素都等于 0 的数组。
返回 k 可以取到的 最小非负 值,使得在 顺序 处理前 k 个查询后,nums 变成 零数组。如果不存在这样的 k,则返回 -1。
示例 1:
输入: nums = [2,0,2], queries = [[0,2,1],[0,2,1],[1,1,3]]
输出: 2
解释:
对于 i = 0(l = 0, r = 2, val = 1):
在下标 [0, 1, 2] 处分别减少 [1, 0, 1]。
数组将变为 [1, 0, 1]。
对于 i = 1(l = 0, r = 2, val = 1):
在下标 [0, 1, 2] 处分别减少 [1, 0, 1]。
数组将变为 [0, 0, 0],这是一个零数组。因此,k 的最小值为 2。示例 2:
输入: nums = [4,3,2,1], queries = [[1,3,2],[0,2,1]]
输出: -1
解释:
对于 i = 0(l = 1, r = 3, val = 2):
在下标 [1, 2, 3] 处分别减少 [2, 2, 1]。
数组将变为 [4, 1, 0, 0]。
对于 i = 1(l = 0, r = 2, val = 1):
在下标 [0, 1, 2] 处分别减少 [1, 1, 0]。
数组将变为 [3, 0, 0, 0],这不是一个零数组。提示:
- 1 <= nums.length <= 10^5
- 0 <= nums[i] <= 5 * 10^5
- 1 <= queries.length <= 10^5
- queries[i].length == 3
- 0 <= li <= ri < nums.length
- 1 <= vali <= 5
思路
有一个长度为 n 的整数数组,每一次操作可以将给定范围内的任意元素 最多 减去 vali = queries[2],计算将数组中的所有元素变为 0 最少需要按顺序操作几次。
与 3355.零数组变换I 相比,求的是最小操作次数,每一次操作都需要判断数组元素是否全为 0,涉及到区间修改与区间查询,可以使用线段树维护区间最大值,每次操作后判断最大值是否大于 0。
官网给出了另一种思路,二分查找操作次数 k,针对每一个 k 问题变成 3355.零数组变换I。
代码
/**
* @date 2025-05-21 9:35
*/
public class MinZeroArray3356 {
public int minZeroArray(int[] nums, int[][] queries) {
int right = queries.length - 1;
int left = -1;
int mid = left + (right - left) / 2;
while (left <= right) {
if (check(nums, mid, queries)) {
right = mid - 1;
} else {
left = mid + 1;
}
mid = left + (right - left) / 2;
}
return left == queries.length ? -1 : left + 1;
}
public boolean check(int[] nums, int k, int[][] queries) {
int n = nums.length;
int[] diff = new int[n + 1];
diff[0] = nums[0];
for (int i = 1; i < n; i++) {
diff[i] = nums[i] - nums[i - 1];
}
for (int i = 0; i <= k; i++) {
int[] query = queries[i];
int val = query[2];
diff[query[0]] -= val;
diff[query[1] + 1] += val;
}
int num = 0;
for (int i = 0; i < n; i++) {
num += diff[i];
if (num > 0) {
return false;
}
}
return true;
}
}
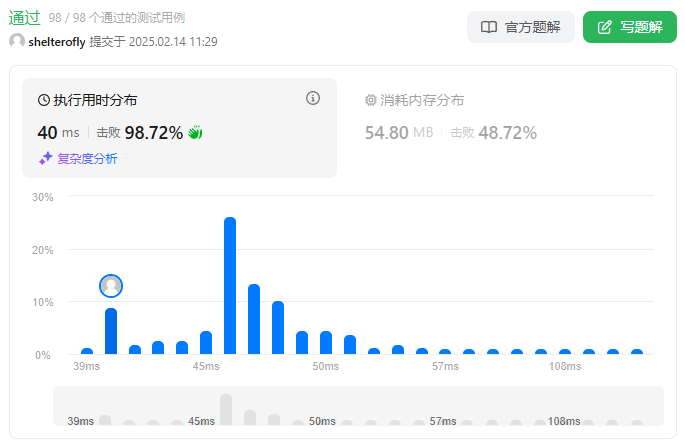
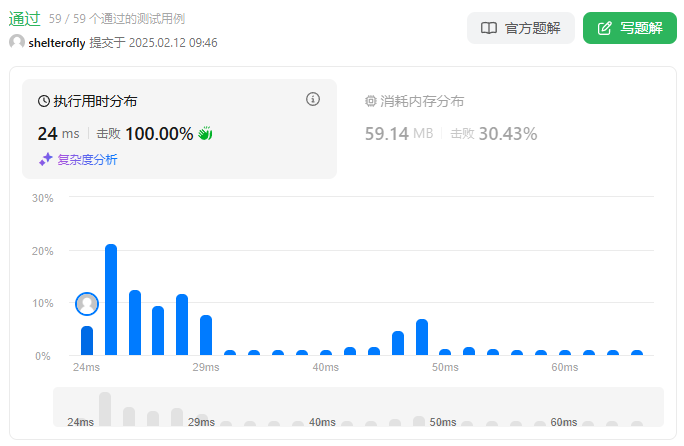
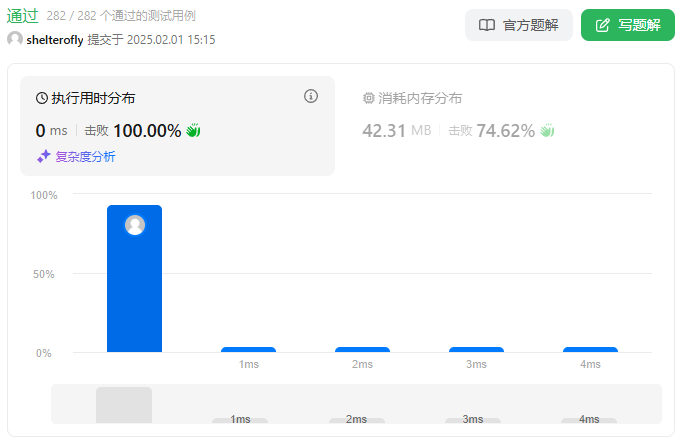
性能