目标
给你一个二叉树的根节点 root。设根节点位于二叉树的第 1 层,而根节点的子节点位于第 2 层,依此类推。
返回总和 最大 的那一层的层号 x。如果有多层的总和一样大,返回其中 最小 的层号 x。
示例 1:
输入:root = [1,7,0,7,-8,null,null]
输出:2
解释:
第 1 层各元素之和为 1,
第 2 层各元素之和为 7 + 0 = 7,
第 3 层各元素之和为 7 + -8 = -1,
所以我们返回第 2 层的层号,它的层内元素之和最大。示例 2:
输入:root = [989,null,10250,98693,-89388,null,null,null,-32127]
输出:2说明:
- 树中的节点数在 [1, 10^4]范围内
- -10^5 <= Node.val <= 10^5
思路
定义二叉树根节点为第 1 层,子节点层号依次累加,求和最大的层号,如果和相同,返回最小的层号。
BFS/DFS 都可以。
代码
/**
* @date 2026-01-06 8:47
*/
public class MaxLevelSum1161 {
public int maxLevelSum(TreeNode root) {
Deque<TreeNode> q = new ArrayDeque<>();
q.offer(root);
int res = 1;
int level = 1;
int max = Integer.MIN_VALUE;
while (!q.isEmpty()) {
int size = q.size();
int sum = 0;
for (int i = 0; i < size; i++) {
TreeNode node = q.poll();
sum += node.val;
if (node.left != null) {
q.offer(node.left);
}
if (node.right != null) {
q.offer(node.right);
}
}
if (max < sum) {
max = sum;
res = level;
}
level++;
}
return res;
}
}
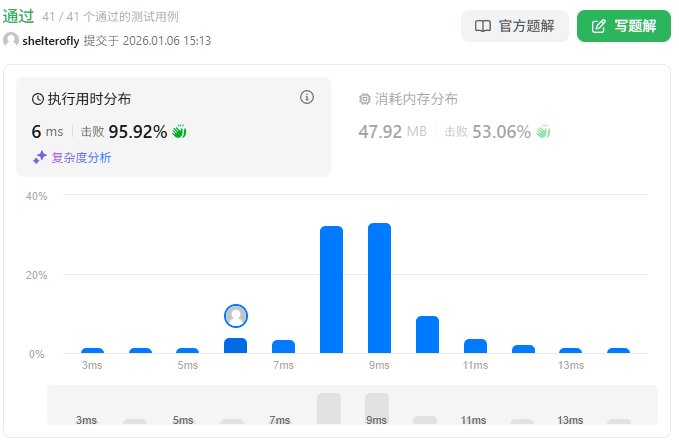
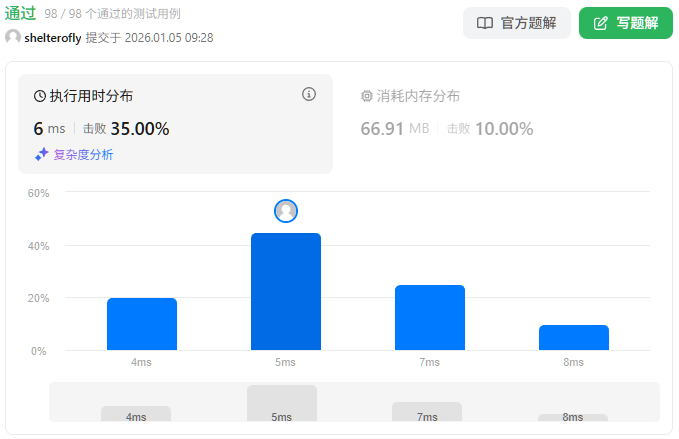
性能