目标
一张桌子上总共有 n 个硬币 栈 。每个栈有 正整数 个带面值的硬币。
每一次操作中,你可以从任意一个栈的 顶部 取出 1 个硬币,从栈中移除它,并放入你的钱包里。
给你一个列表 piles ,其中 piles[i] 是一个整数数组,分别表示第 i 个栈里 从顶到底 的硬币面值。同时给你一个正整数 k ,请你返回在 恰好 进行 k 次操作的前提下,你钱包里硬币面值之和 最大为多少 。
示例 1:

输入:piles = [[1,100,3],[7,8,9]], k = 2
输出:101
解释:
上图展示了几种选择 k 个硬币的不同方法。
我们可以得到的最大面值为 101 。示例 2:
输入:piles = [[100],[100],[100],[100],[100],[100],[1,1,1,1,1,1,700]], k = 7
输出:706
解释:
如果我们所有硬币都从最后一个栈中取,可以得到最大面值和。说明:
- n == piles.length
- 1 <= n <= 1000
- 1 <=
piles[i][j]<= 10^5 - 1 <= k <= sum(piles[i].length) <= 2000
思路
有 n 个栈,栈中有 piles[i].length 个硬币,每次操作可以从任意栈顶取一个硬币,求 k 次操作取得的硬币和的最大值。
定义 dp[i][j] 表示 从前 i + 1 个栈中最多取 j 个 所能得到的最大值,与 0 - 1 背包不同的是我们需要枚举从当前栈取 1 至 x 枚硬币的最大值,状态转移方程为 dp[i][j] = Math.max(dp[i][j], Math.max(dp[i - 1][j], dp[i - 1][j - x] + prefix[i][x])),外层 max 求的是当前栈每种取法的最大值,第二个参数的 max 求的是当前栈 不取 或者 取 x 枚硬币对应的最大值。由于是从栈顶取,我们使用前缀和 prefix 记录每个栈从栈顶到底的硬币和。
代码
/**
* @date 2025-01-21 13:46
*/
public class MaxValueOfCoins2218 {
public int maxValueOfCoins(List<List<Integer>> piles, int k) {
int n = piles.size();
int[][] prefix = new int[n][];
// 计算前缀和
for (int i = 0; i < n; i++) {
List<Integer> pile = piles.get(i);
prefix[i] = new int[pile.size() + 1];
for (int j = 1; j <= pile.size(); j++) {
prefix[i][j] = prefix[i][j - 1] + pile.get(j - 1);
}
}
// 定义dp[i][j] 表示 从前 i + 1 个栈中最多取 j 个 所能得到的最大值
int[][] dp = new int[n][k + 1];
// 初始化,从第一个栈最多取 k 个
for (int j = 1; j <= k; j++) {
int length = piles.get(0).size();
if (j <= length) {
dp[0][j] = prefix[0][j];
} else {
dp[0][j] = dp[0][length];
}
}
for (int i = 1; i < n; i++) {
// 枚举右边界
int length = piles.get(i).size();
for (int j = 1; j <= k; j++) {
// j 表示从前 i + 1 个栈中总共取 j 个
for (int x = 1; x <= length && j >= x; x++) {
// 表示从当前栈中取 x 个
dp[i][j] = Math.max(dp[i][j], Math.max(dp[i - 1][j], dp[i - 1][j - x] + prefix[i][x]));
}
}
}
return dp[n - 1][k];
}
}
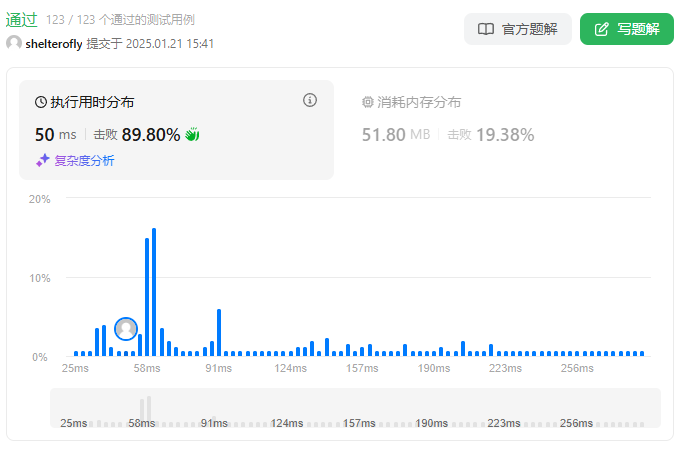
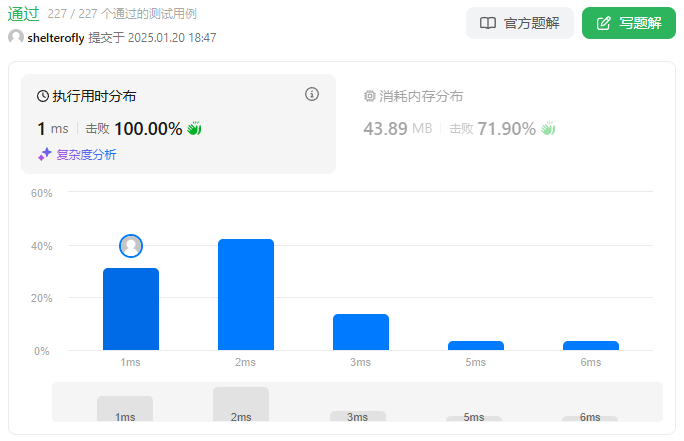
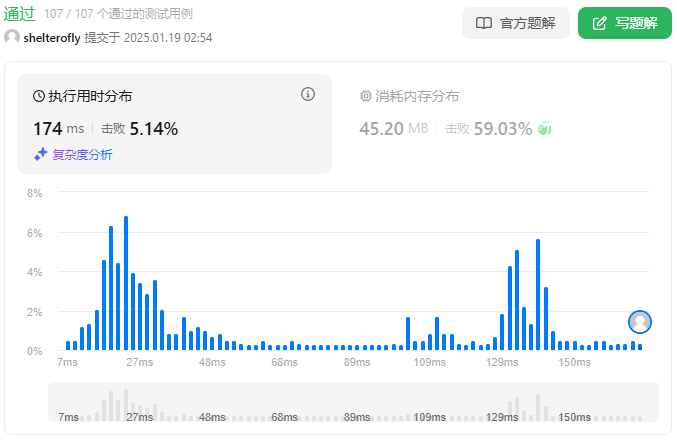
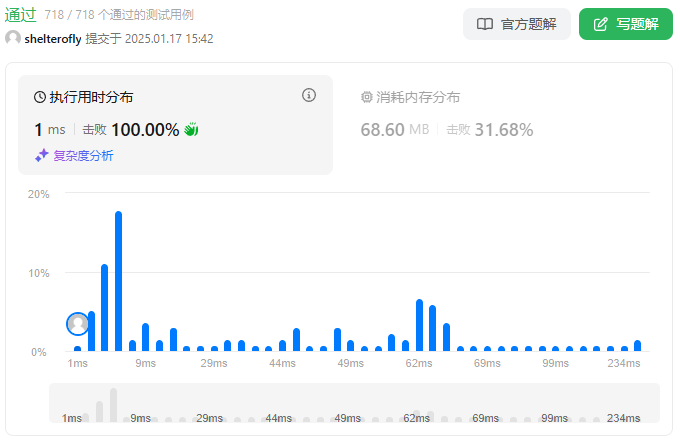
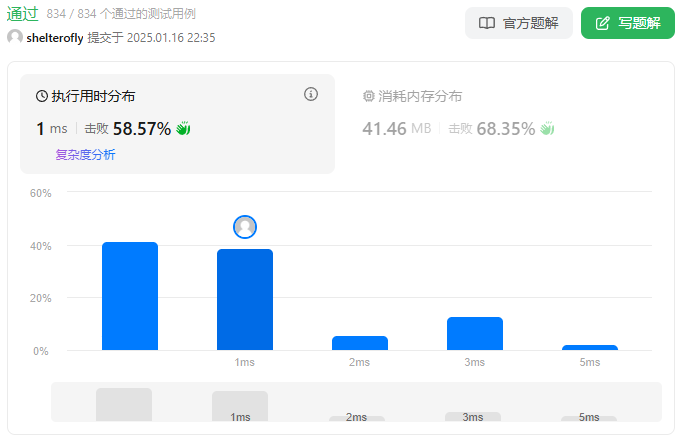
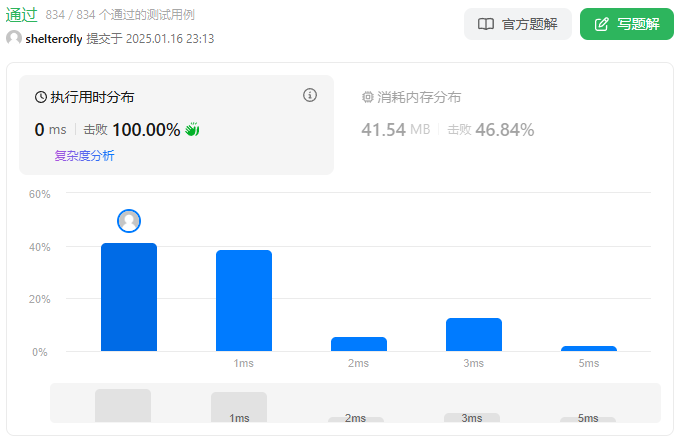
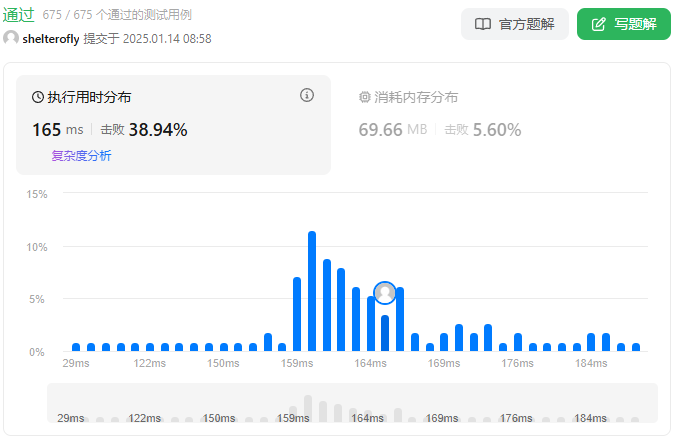
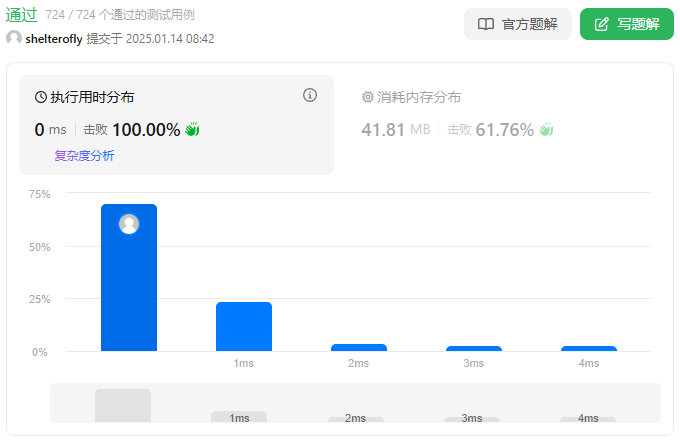
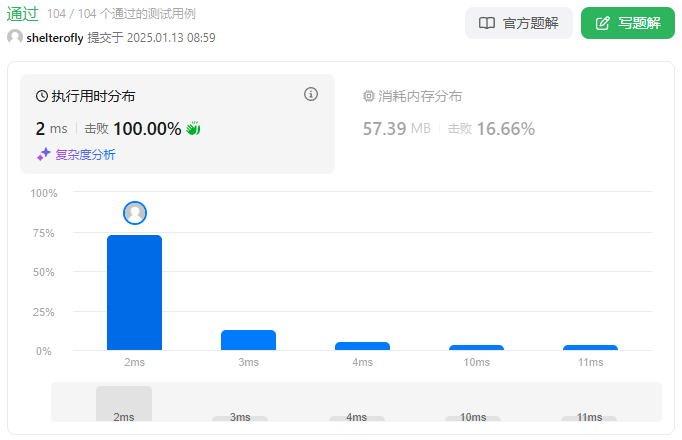
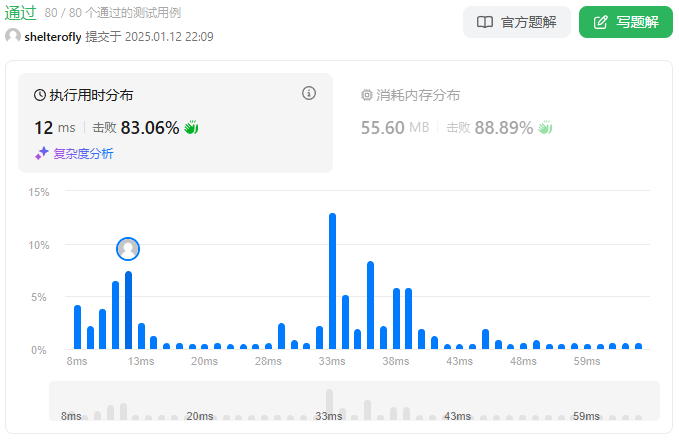
性能