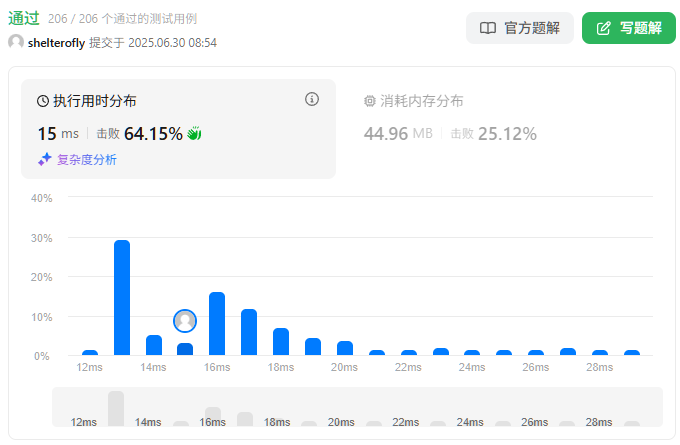
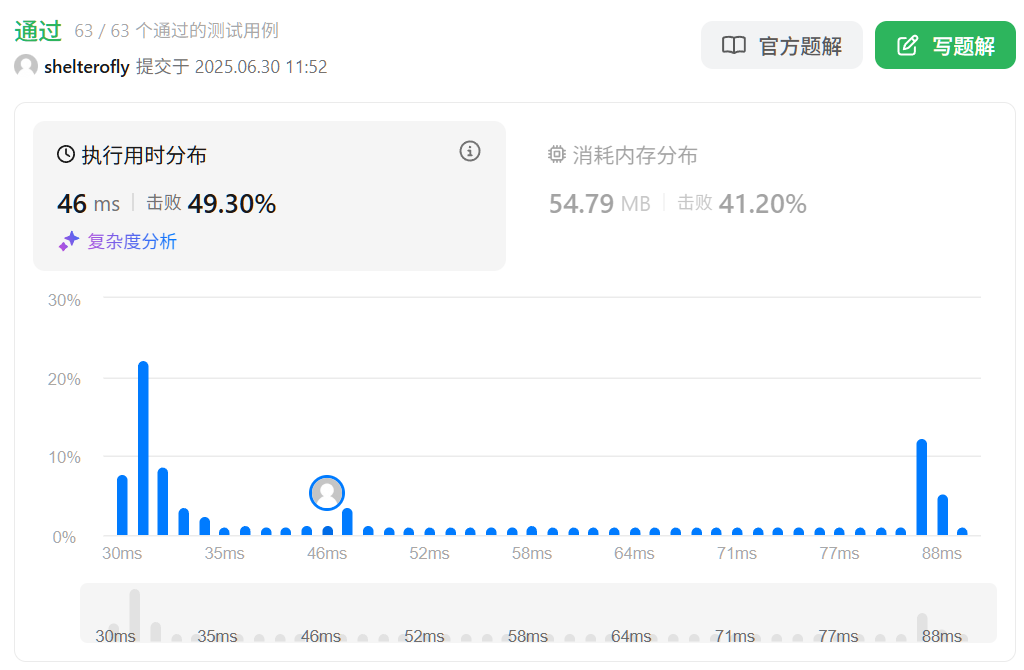
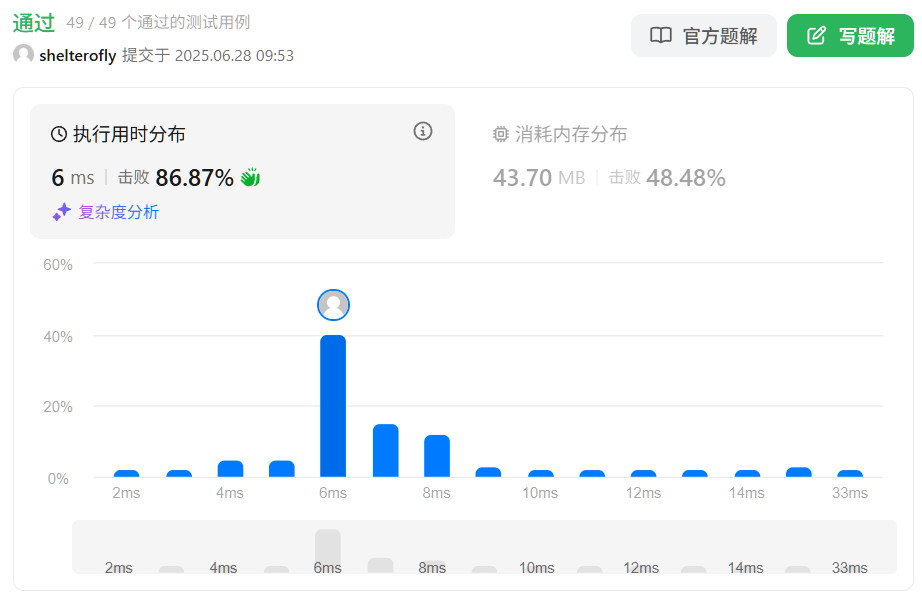
目标
和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。
给你一个整数数组 nums ,请你在所有可能的 子序列 中找到最长的和谐子序列的长度。
数组的 子序列 是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素、且不改变其余元素的顺序而得到。
示例 1:
输入:nums = [1,3,2,2,5,2,3,7]
输出:5
解释:
最长和谐子序列是 [3,2,2,2,3]。示例 2:
输入:nums = [1,2,3,4]
输出:2
解释:
最长和谐子序列是 [1,2],[2,3] 和 [3,4],长度都为 2。示例 3:
输入:nums = [1,1,1,1]
输出:0
解释:
不存在和谐子序列。说明:
- 1 <= nums.length <= 2 * 10^4
- -10^9 <= nums[i] <= 10^9
思路
统计数字出现次数,求相邻频次之和的最大值。
代码
/**
* @date 2025-06-30 8:46
*/
public class FindLHS {
public int findLHS(int[] nums) {
int n = nums.length;
Map<Integer, Integer> cnt = new HashMap<>();
for (int i = 0; i < n; i++) {
cnt.merge(nums[i], 1, Integer::sum);
}
int res = 0;
for (Map.Entry<Integer, Integer> entry : cnt.entrySet()) {
int key = entry.getKey();
Integer nextVal = cnt.get(key + 1);
if (nextVal != null) {
res = Math.max(res, entry.getValue() + nextVal);
}
}
return res;
}
}
性能